[Web] REST vs GraphQL vs gRPC
소프트웨어 아키텍처의 역사는 곧 ‘소통의 경계’를 획정해온 기록입니다. 초기의 모놀리식 시스템 내부에서 함수 호출(Function Call)로 해결되던 데이터 흐름은, 시스템이 물리적으로 파편화되고 네트워크라는 불확실한 매개를 사이에 두게 되면서 거대한 전환점을 맞이했습니다. 이제 통신은 단순히 바이트를 옮기는 행위를 넘어, 서로 다른 생존 주기를 가진 독립된 개체들이 신뢰를 구축하는 ‘사회적 약속’이 되었습니다.
우리는 흔히 REST를 표준으로 삼아왔지만, 이는 웹의 보편성이라는 거인의 어깨 위에 올라탄 결과일 뿐 모든 문제의 정답은 아니었습니다. 시스템의 복잡도가 임계점을 넘어서면서, 엔지니어들은 두 가지 극단적인 갈림길에 서게 됩니다. 하나는 클라이언트에게 극도의 자율성을 부여하여 런타임의 유연성을 확보하는 ‘GraphQL’의 길이고, 다른 하나는 기계적인 엄격함과 이진 효율성을 통해 통신의 밀도를 극한으로 끌어올리는 ‘gRPC’의 길입니다.
현대의 분산 시스템은 수천 개의 커넥션이 동시에 얽히며 CPU 사이클의 상당 부분을 네트워크 I/O와 직렬화(Serialization)에 소모합니다. 이러한 환경에서 인터페이스의 분화는 단순한 취향의 차이가 아니라, 인프라 비용과 시스템의 응답성이라는 생존 전략으로 이어집니다.
🧩 REST
REST(Representational State Transfer)는 아키텍처 스타일이기 이전에, 이미 거대하게 성공한 웹(Web)의 동작 원리를 시스템 간 통신에 이식하려는 시도였습니다. 로이 필딩(Roy Fielding)이 정의한 이 규약의 핵심은 ‘제약 조건을 통한 자유’에 있습니다. 특정 기술에 종속되지 않고 HTTP라는 범용적인 인터페이스를 활용함으로써, REST는 지난 20여 년간 분산 시스템의 가장 강력한 표준으로 자리 잡았습니다.
Uniform Interface
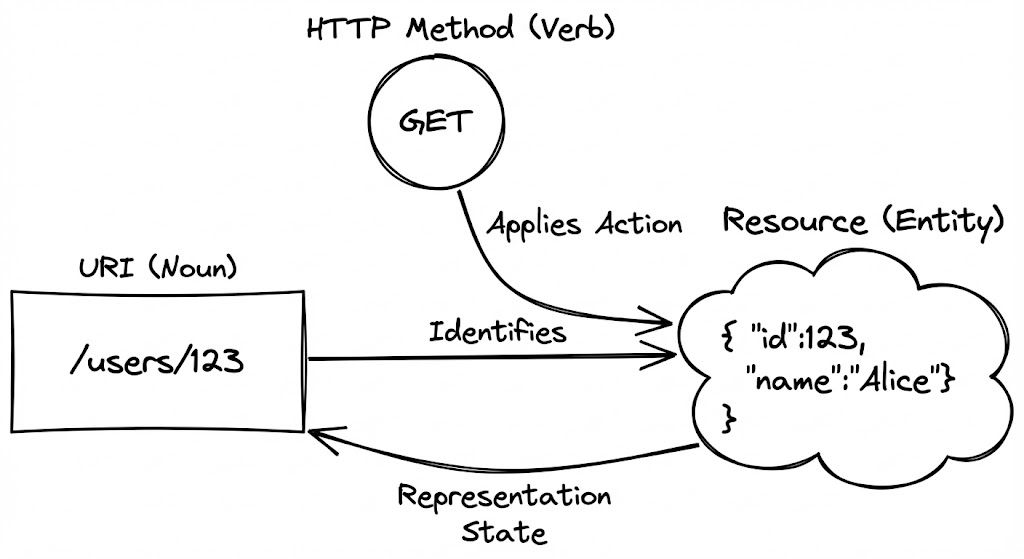
REST 설계에서 가장 흔하게 저지르는 실수는 URL에 동사를 포함하는 것입니다. 하지만 REST의 본질은 ‘동작’이 아니라 ‘상태’에 있습니다. 모든 것은 리소스(Resource)로 표현되어야 하며, URL은 그 리소스를 가리키는 고유한 식별자(ID) 역할을 수행합니다.
우리가 /getUserData 대신 /users/123을 사용해야 하는 이유는 인터페이스의 예측 가능성 때문입니다. HTTP 메서드(GET, POST, PUT, DELETE)라는 표준화된 동사가 존재하기에, 리소스를 가리키는 명사만으로도 해당 요청의 의도가 완벽하게 전달됩니다. 이는 서버와 클라이언트 사이의 인지적 부하를 줄여주는 ‘보편적 문법’이 됩니다.
캐시와 무상태성
REST가 대규모 트래픽을 견디는 방식은 ‘무상태성(Statelessness)’에서 기원합니다. 각 요청은 독립적이며, 서버는 클라이언트의 이전 상태를 기억할 의무가 없습니다. 이 단순한 제약은 서버의 수평적 확장(Scale-out)을 극도로 용이하게 만듭니다. 어떤 서버가 요청을 처리하든 결과가 동일하기 때문입니다.
더 나아가, REST의 ‘캐시 가능성(Cacheability)’은 폭발적인 트래픽 상황에서 시스템을 보호하는 최후의 보루입니다. 읽기 비중이 압도적인 서비스에서 HTTP 표준 캐시 헤더를 활용하면, 요청이 데이터베이스까지 도달하기 전에 인프라 레벨(CDN, Proxy)에서 쳐낼 수 있습니다. 이는 트래픽이 집중되는 극한의 상황에서도 시스템을 지탱하는 핵심 메커니즘이 됩니다.
무상태 설계의 트레이드오프
모든 요청에 인증 토큰과 필요한 컨텍스트를 포함해야 하므로, 네트워크 페이로드가 다소 무거워질 수 있습니다. 하지만 이는 서버의 복잡도를 낮추고 복구 탄력성을 얻기 위해 지불하는 정당한 비용입니다.
HATEOAS와 ‘RESTish’의 현실
진정한 REST의 정점은 HATEOAS(Hypermedia As The Engine Of Application State)에 있습니다. 응답 데이터 내에 다음에 수행할 수 있는 동작들의 링크를 포함하여, 클라이언트가 애플리케이션의 상태 변화를 스스로 탐색하게 만드는 것입니다.
하지만 실무에서 이를 완벽히 구현하는 경우는 극히 드뭅니다. 대부분의 엔지니어는 리소스 경로와 메서드만 준수하는 ‘RESTish’ 수준에서 타협합니다. 이는 HATEOAS를 구현하기 위해 치러야 하는 구현 복잡도와 클라이언트의 파싱 오버헤드가, 그로 인해 얻는 유연성보다 크다고 판단하기 때문입니다. REST가 웹의 철학을 표방하면서도, 현실에서는 실용주의적 도구로 변모해온 과정을 단적으로 보여주는 지점입니다.
🧩 GraphQL
REST가 서버가 정해준 메뉴판대로만 음식을 받아야 하는 ‘정찰제 식당’이라면, GraphQL은 클라이언트가 장바구니를 들고 원하는 재료만 골라 담는 ‘장보기 대행’ 서비스에 가깝습니다. 2012년 페이스북이 모바일 환경의 네트워크 효율성을 극대화하기 위해 설계한 이 언어는, 엔드포인트 중심의 통신을 ‘그래프(Graph)’ 중심의 질서로 재편했습니다.
Query Execution 런타임
GraphQL의 마법은 서버와 클라이언트 사이의 ‘강력한 계약(Schema)’에서 시작됩니다. 하지만 그 이면에서 실제로 작동하는 핵심은 쿼리 실행(Query Execution) 런타임입니다. 클라이언트가 복잡하게 얽힌 쿼리를 던지면, 서버는 이를 트리 구조로 파싱하고 각 필드에 매핑된 ‘리졸버(Resolver)’ 함수를 호출합니다.
이 과정에서 GraphQL은 REST의 고질적인 병목인 Over-fetching(불필요한 데이터 수신)과 Under-fetching(여러 번의 요청 필요)을 단번에 해결합니다. 클라이언트는 오직 화면 렌더링에 필요한 필드만 정의하며, 서버는 그 정의에 정확히 부합하는 JSON 객체를 조립하여 단 한 번의 라운드 트립(Round-trip)으로 반환합니다.
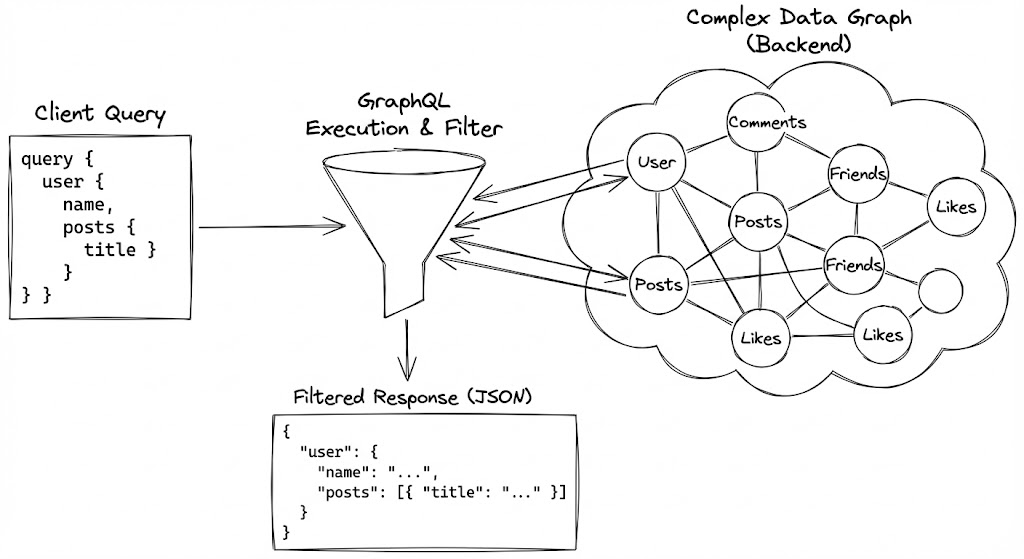
N+1 문제와 데이터 로더
유연성에는 반드시 대가가 따릅니다. GraphQL의 가장 치명적인 약점은 역설적으로 그 자유로운 쿼리 구조에서 기인하는 ‘N+1 문제’입니다. 예를 들어, 10개의 게시글(Post)과 각 게시글의 작성자(Author) 정보를 가져올 때, 나이브하게 구현된 리졸버는 1번의 게시글 조회 후 10번의 작성자 조회 쿼리를 개별적으로 실행하게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
/**
* 1. REST API: 여러 엔드포인트를 순차적으로 호출 (N+1 문제의 클라이언트측 체감)
* Spring RestTemplate 또는 WebClient를 사용하는 전형적인 방식
*/
public PostResponse fetchPostWithAuthorREST(Long postId) {
// 첫 번째 호출: 게시글 정보 조회
Post post = restTemplate.getForObject("/api/posts/" + postId, Post.class);
// Under-fetching: 작성자 상세 정보가 없어 두 번째 호출이 강제됨
Long authorId = post.getAuthorId();
Author author = restTemplate.getForObject("/api/authors/" + authorId, Author.class);
return PostResponse.from(post, author);
}
/**
* 2. GraphQL: 단일 쿼리로 원하는 그래프 구조를 한 번에 획득
* 자바 클라이언트는 필요한 필드만 정의된 쿼리를 문자열 또는 .graphql 파일로 전송
*/
String graphQLQuery = """
query GetPostDetail($id: ID!) {
post(id: $id) {
title
content
author {
name
avatarUrl
}
}
}
""";
// 서버 측에서는 'author' 리졸버가 내부적으로 작동하여 단일 응답(JSON)을 조립함
이를 해결하기 위해 대규모 시스템은 ‘데이터 로더(DataLoader)’ 패턴을 필수적으로 채택합니다. 데이터 로더는 짧은 시간 동안 발생하는 개별 요청을 수집(Batching)하고, 중복된 요청을 제거(Caching)하여 단일 데이터베이스 쿼리로 변환합니다. 이는 런타임의 유연성을 유지하면서도 인프라 부하를 지능적으로 관리하는 GraphQL 생태계의 핵심 기술입니다.
유연성이 만드는 복잡도
GraphQL은 클라이언트 개발자의 생산성을 폭발적으로 높여주지만, 그 복잡도는 고스란히 서버 아키텍처로 전이됩니다. 복잡한 쿼리에 대한 가변적인 응답 시간을 예측하고, 악의적인 깊은 쿼리(Deep Query)로부터 서버를 보호하기 위한 쿼리 복잡도 제한(Query Complexity Analysis)은 필수적인 운영 요소입니다.
🧩 gRPC
REST가 인간이 읽기 편한 문서를 주고받는 과정이라면, gRPC는 기계와 기계가 서로의 뇌를 직접 연결하는 고속 데이터 버스에 가깝습니다. 구글이 내부 통신 프레임워크인 Stubby를 오픈소스화하며 세상에 나온 gRPC는, 웹 브라우저라는 범용적 환경을 넘어 마이크로서비스 간의 초고속, 고밀도 통신을 위해 설계되었습니다.
IDL과 코드 생성
gRPC의 가장 큰 패러다임 전환은 ‘Contract-First’ 개발 모델에 있습니다. REST가 API 문서를 사후에 작성(Swagger 등)하는 것과 달리, gRPC는 IDL(Interface Definition Language)인 Protocol Buffers를 사용하여 인터페이스를 먼저 정의합니다.
이 .proto 파일은 단순한 문서가 아닙니다. 이 명세는 수천 개의 마이크로서비스 사이에서 ‘절대적인 진실’로 작동합니다. 컴파일 타임에 각 언어(Go, Java, Python 등)에 맞는 클라이언트 스텁(Stub)과 서버 인터페이스 코드가 자동으로 생성되므로, 개발자는 네트워크 통신의 하부 구조를 고민할 필요 없이 비즈니스 로직에만 집중할 수 있습니다. 이는 “런타임에 어떤 필드가 올지 기도하는” 방식에서 벗어나, 컴파일러가 타입 안정성을 보장하는 강력한 결합을 제공합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// user.proto: 언어 중립적 인터페이스 정의
syntax = "proto3";
option java_multiple_files = true;
option java_package = "com.example.grpc.user";
service UserService {
rpc GetUser (UserRequest) returns (UserResponse);
}
message UserRequest {
string user_id = 1;
}
message UserResponse {
string id = 1;
string name = 2;
int32 age = 3;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
/**
* gRPC Java 서버 구현 예시
* IDL(proto)에서 자동 생성된 'UserServiceImplBase'를 상속받아 비즈니스 로직 구현
*/
@GrpcService
public class UserServiceImpl extends UserServiceImplBase {
@Override
public void getUser(UserRequest request, StreamObserver<UserResponse> responseObserver) {
// 타입 안정성이 보장된 요청 객체 (request.getUserId())
UserResponse response = UserResponse.newBuilder()
.setId(request.getUserId())
.setName("Alice")
.setAge(25)
.build();
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
Protocol Buffers
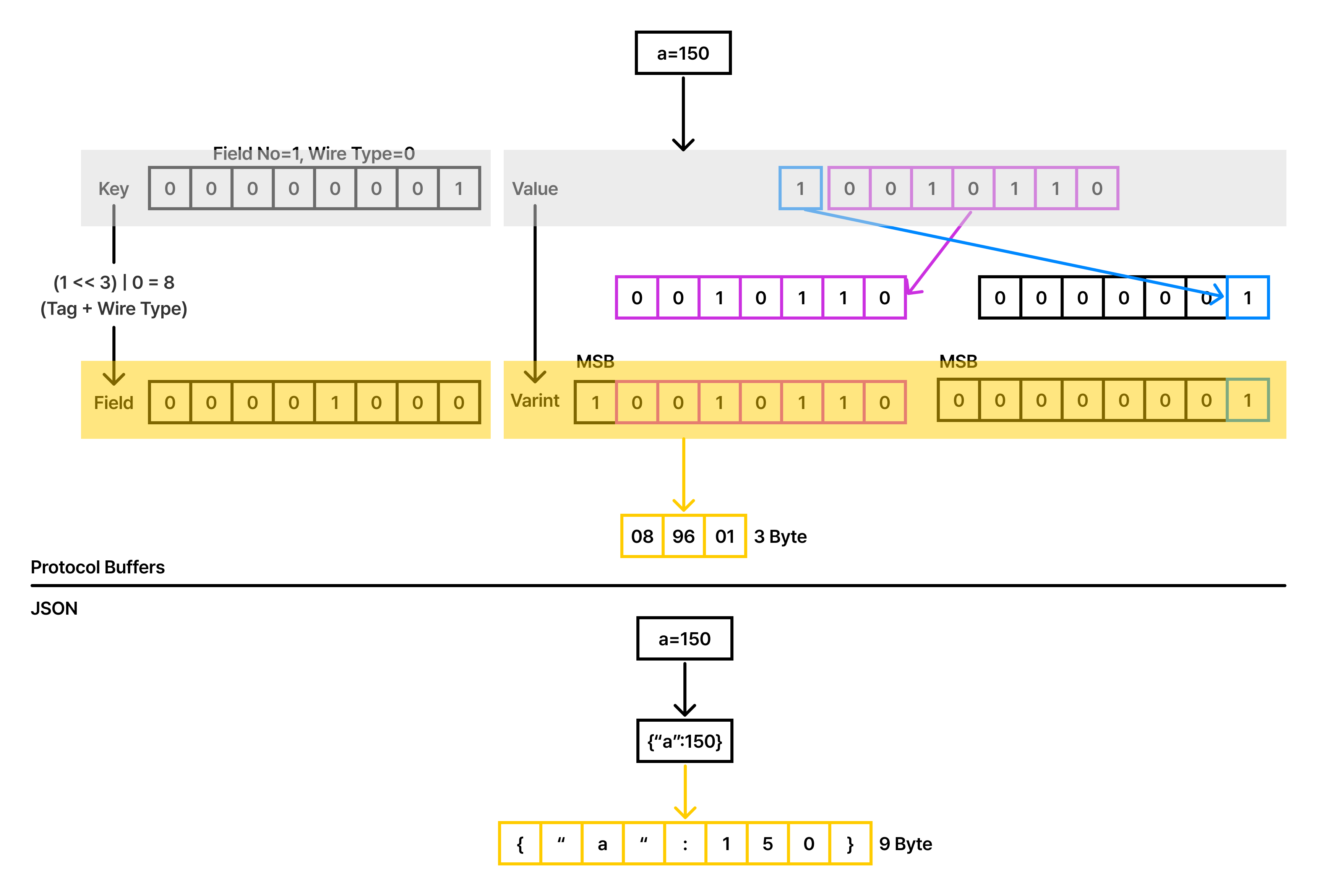
JSON은 훌륭한 범용 포맷이지만, 컴퓨터의 관점에서는 매우 비효율적입니다. {"age": 25}라는 데이터를 보낼 때, 정수 25를 보내기 위해 ‘a’, ‘g’, ‘e’, ‘:’, ‘2’, ‘5’라는 6개의 텍스트 바이트와 괄호 스캔이 필요합니다. 이러한 텍스트 파싱 과정은 CPU 클락을 의미 없이 소모하며 메모리 할당 오버헤드를 유발합니다.
반면 gRPC가 사용하는 Protocol Buffers(Protobuf)는 데이터를 이진(Binary) 형태로 압축합니다. 필드 이름 대신 숫자로 된 태그를 사용하고, 정수는 가변 길이 인코딩(Varint)으로 처리하여 페이로드 크기를 JSON 대비 30~50% 이상 줄입니다. 이는 단순한 네트워크 대역폭 절약을 넘어, 데이터의 직렬화/역직렬화에 소모되는 CPU 사이클을 혁신적으로 단축하여 전체 시스템의 처리량(Throughput)을 끌어올립니다.
HTTP/2 기반의 풀-듀플렉스 통신
gRPC가 REST보다 압도적으로 강력한 지점은 그 하부 레이어인 HTTP/2에 있습니다. HTTP/1.1이 하나의 요청이 끝나야 다음 요청을 보낼 수 있는 순차적 구조였다면, HTTP/2는 단일 커넥션 위에서 수많은 요청과 응답이 ‘프레임(Frame)’ 단위로 쪼개져 동시에 오가는 멀티플렉싱(Multiplexing)을 지원합니다.
이 구조는 gRPC에게 양방향 스트리밍(Bi-directional Streaming)이라는 날개를 달아줍니다. 서버가 클라이언트의 요청 없이도 데이터를 밀어내거나(Server Push), 클라이언트가 대용량 데이터를 끊김 없이 쏘아 올리는 것이 가능해집니다. 이는 실시간 푸시 플랫폼이나 고빈도 로그 수집 시스템에서 gRPC가 독보적인 선택지가 되는 이유입니다.
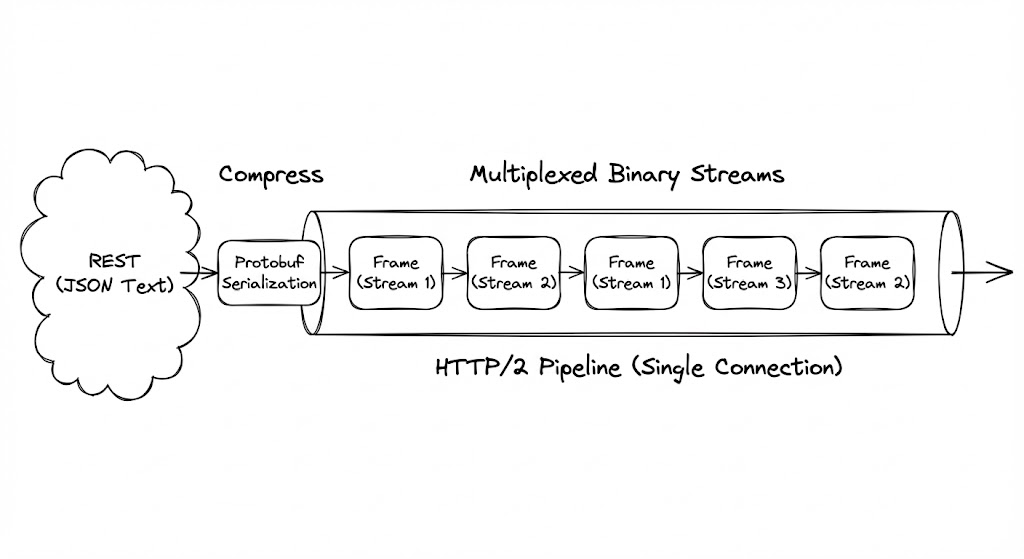
바이너리의 폐쇄성
gRPC의 압도적 효율은 ‘가독성’을 제물로 바친 결과입니다. 웹 브라우저의 개발자 도구로 네트워크 패킷을 들여다봐도 의미를 알 수 없는 바이너리 덩어리만 보일 뿐입니다. 따라서 디버깅을 위해서는 전용 도구(grpcurl 등)와 Protobuf 명세서가 반드시 수반되어야 합니다.
유연성이냐 안정성이냐
엔지니어링에서 결합도(Coupling)는 단순히 코드 간의 의존성을 넘어, 팀과 팀 사이의 ‘사회적 계약’의 강도를 결정합니다. 통신 규약을 선택하는 행위는 우리가 시스템의 변화를 수용할 때 ‘유연성’이라는 이름의 자유를 누릴 것인지, 아니면 ‘안정성’이라는 이름의 질서를 선택할 것인지를 결정하는 아키텍처적 선언입니다.
REST와 런타임의 유령
REST의 가장 큰 매력은 ‘느슨한 결합(Loose Coupling)’에 있습니다. 서버는 특정 구조의 JSON을 던지고, 클라이언트는 그중 필요한 필드만 골라 씁니다. 이러한 ‘Schema-on-read’ 방식은 초기 개발 단계에서 압도적인 속도를 부여합니다. 서버가 필드를 추가해도 클라이언트는 깨지지 않으며, 양측은 서로의 배포 주기에 크게 관여하지 않습니다.
하지만 시스템의 규모가 커지고 서비스가 수백 개로 파편화되면, 이 유연성은 ‘런타임 리스크’라는 부메랑으로 돌아옵니다. 명시적인 스키마(Schema)가 없기 때문에, 서버 개발자가 필드명을 user_id에서 userId로 바꾸는 사소한 실수를 저지르는 순간, 이를 구독하던 수십 개의 서비스는 런타임 에러를 뱉으며 무너집니다. REST 환경에서의 안정성은 오직 ‘문서화의 성실함’과 ‘테스트 코드의 꼼꼼함’이라는 인간의 의지에 의존하게 됩니다.
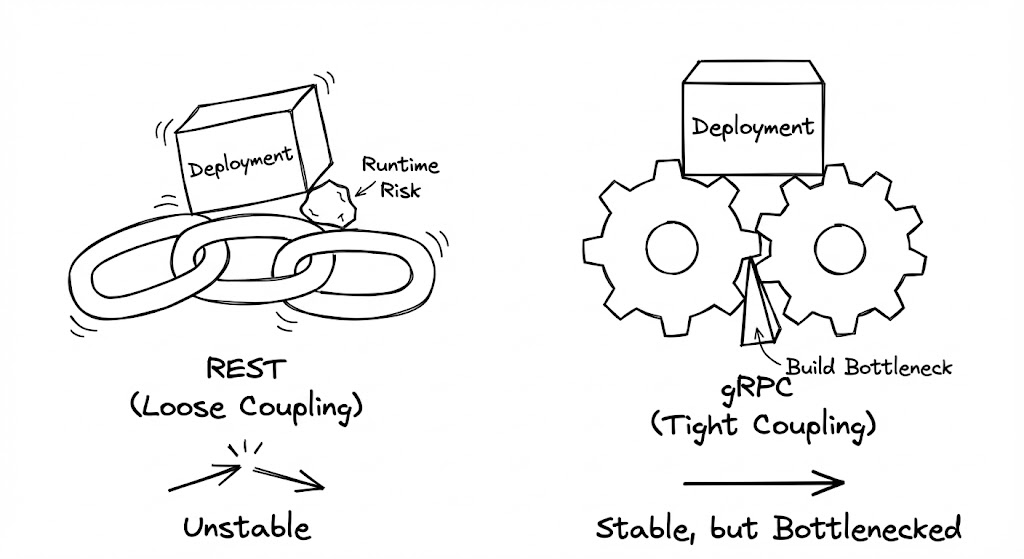
gRPC와 배포 병목의 역설
반면 gRPC는 ‘강한 결합(Tight Coupling)’을 지향합니다. IDL(Interface Definition Language)을 통해 정의된 계약은 컴파일 타임에 검증됩니다. 서버가 계약을 어기는 코드를 작성하면 빌드 자체가 실패합니다. 이러한 엄격함은 대규모 조직에서 ‘타입 안정성’이라는 달콤한 안식을 제공합니다.
그러나 이 질서에는 ‘배포의 경직성’이라는 대가가 따릅니다. gRPC 명세를 변경하려면 양측 모두가 새로운 코드를 생성(Code Gen)하고 배포해야 합니다. 특히 모바일 앱처럼 배포 주기를 서버 마음대로 조절할 수 없는 환경에서는, 하위 호환성(Backward Compatibility)을 유지하기 위해 프로토콜 버전을 관리하는 운영 오버헤드가 기하급수적으로 증가합니다. 강한 결합이 주는 안정성이 때로는 전체 시스템의 민첩성을 저해하는 ‘배포의 병목’이 되는 역설적인 상황이 발생합니다.
REST와 gRPC 중 어느 시점에 비용을 지불할 것인가?
REST는 ‘나중에 지불하는 비용(장애 대응)’을 담보로 현재의 속도를 얻는 기술이고, gRPC는 ‘미리 지불하는 비용(엄격한 설계와 코드 생성)’을 통해 미래의 평화를 사는 기술입니다. 우리 팀이 감당할 수 있는 비용의 시점이 언제인지 파악하는 것이 아키텍트의 핵심 역량입니다.
바이너리는 정말 ‘그냥’ 빠른가
성능을 논할 때 우리는 흔히 “바이너리(Binary)가 텍스트보다 빠르다”는 결론을 성급하게 내리곤 합니다. 하지만 엔지니어링의 관점에서 중요한 것은 ‘왜’ 빠른지, 그리고 그 대가로 무엇을 희생하는지 그 실체를 파헤치는 것입니다. 데이터 통신의 효율성은 단순히 전송되는 바이트의 크기가 아니라, CPU가 데이터를 해석하기 위해 지불하는 ‘계산 비용’에 달려 있습니다.
JSON 파싱 vs Protobuf 언마샬링
우리가 매일 사용하는 JSON은 인간에게는 축복이지만, CPU에게는 가혹한 노동을 강요합니다. JSON 파싱은 가변적인 문자열 길이를 계산하고, 특수 문자를 이스케이프하며, 텍스트 형태의 숫자를 이진수로 변환하는 과정에서 수많은 CPU 사이클을 점유합니다. 특히 객체의 크기가 커질수록 힙(Heap) 메모리 할당 빈도가 높아지며 가비지 컬렉션(GC)의 압박을 가중시킵니다.
반면 gRPC의 Protocol Buffers는 ‘예측 가능성’의 경제를 따릅니다. 데이터는 필드 번호(Tag)와 고정된 오프셋을 가진 이진 스트림으로 전송됩니다. 언마샬링 과정에서 CPU는 단순히 메모리 주소를 건너뛰며(Offset-based access) 값을 읽기만 하면 됩니다. 이는 단순한 속도 차이를 넘어, 시스템의 전체적인 CPU 점유율을 낮추어 동일한 하드웨어에서 더 많은 요청을 처리할 수 있는 여유(Headroom)를 만들어냅니다.
직렬화 오버헤드의 실체
고부하 환경에서 JSON 직렬화 및 파싱에 소요되는 시간은 전체 응답 시간의 최대 30~40%를 차지하기도 합니다. gRPC 도입만으로 응답 속도가 개선되는 핵심 원인은 네트워크 속도보다 이 ‘CPU 효율성’에 있습니다.
HTTP/2 Multiplexing Trade-off
gRPC의 기반인 HTTP/2는 단일 TCP 커넥션 위에서 여러 스트림을 이진 프레임(Binary Frame) 단위로 쪼개어 교차 배치(Interleaving)합니다. 이는 HTTP/1.1이 가졌던 애플리케이션 계층의 ‘Head-of-Line(HOL) Blocking’을 해결하여, 하나의 느린 요청이 전체 통신을 중단시키지 않도록 설계되었습니다. 하지만 이 효율성은 네트워크 레이어의 신뢰성을 담보하는 TCP의 ‘순서 보장’ 특성과 충돌하며 치명적인 역설을 만들어냅니다.
TCP 레이어의 HOL Blocking
네트워크 혼잡으로 인해 스트림 A의 패킷 하나가 유실되면, TCP 프로토콜은 데이터의 무결성을 위해 뒤따라오는 스트림 B와 C의 패킷이 정상적으로 도착했더라도 이를 애플리케이션 계층으로 올리지 않고 커널 버퍼(Kernel Buffer)에 묶어둡니다. 유실된 A 패킷이 재전송(Retransmission)되어 도착할 때까지 아무런 문제가 없는 다른 데이터들까지 함께 멈춰 서는 ‘전체 전송 중단’ 현상이 발생하는 것입니다.
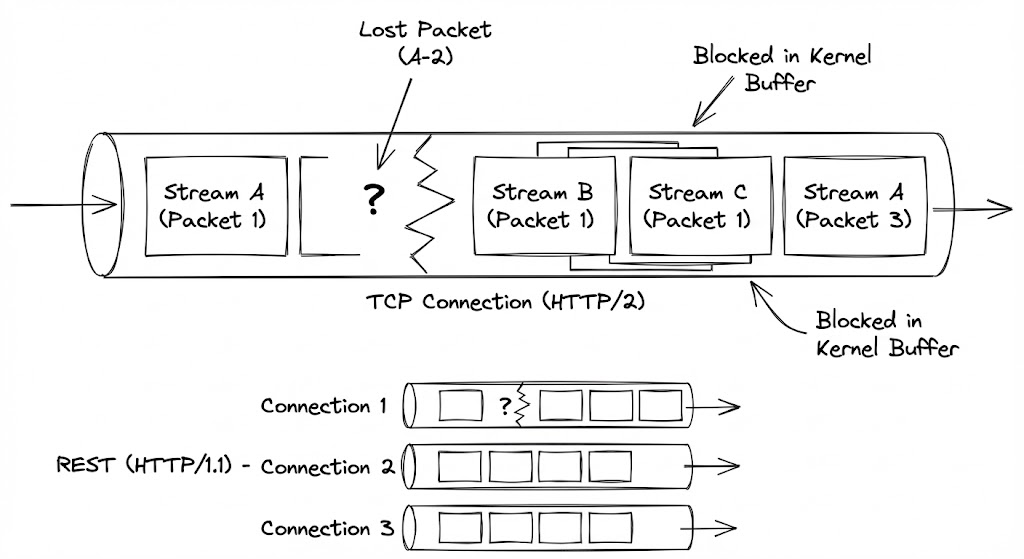
이러한 현상은 패킷 유실률이 높은 열악한 네트워크 환경(모바일 음영 지역, 혼잡한 공용 Wi-Fi 등)에서 gRPC의 꼬리 지연 시간(Tail Latency)을 REST보다 기하급수적으로 악화시킵니다. 여러 개의 TCP 커넥션을 독립적으로 운용하는 REST는 특정 패킷이 유실되어도 해당 커넥션만 영향을 받을 뿐, 다른 커넥션을 통한 통신은 중단 없이 지속되는 ‘장애 격리’ 효과를 누리기 때문입니다.
네트워크 환경에 따른 프로토콜 탄력성
데이터 센터 내부(Intra-DC)와 같이 지연 시간이 짧고 손실률이 0%에 가까운 환경에서는 gRPC가 압도적인 우위를 점합니다. 그러나 불안정한 엔드포인트 간 통신에서는 REST의 고전적인 방식이 오히려 더 높은 가용성을 제공할 수 있습니다.
프로토콜별 통신 특성 비교 매트릭스
| 분석 지표 | REST (HTTP/1.1) | GraphQL (HTTP/1.1) | gRPC (HTTP/2) |
|---|---|---|---|
| 페이로드 최적화 | 낮음 (텍스트 오버헤드) | 중간 (필드 선택 가능) | 매우 높음 (바이너리 압축) |
| CPU 효율 | 낮음 (문자열 파싱) | 중간 (리졸버 연산) | 매우 높음 (이진 디코딩) |
| 동시성 모델 | 커넥션 풀링 (독립적) | 커넥션 풀링 (독립적) | 멀티플렉싱 (커넥션 공유) |
| 패킷 유실 대응 | 강함 (부분 장애) | 강함 (부분 장애) | 약함 (전체 스트림 영향) |
네트워크 경제학의 관점에서 gRPC는 전용 고속도로와 같습니다. 도로 상태가 완벽할 때는 압도적인 물동량을 자랑하지만, 사고(패킷 유실)가 발생하는 순간 고속도로 전체가 거대한 주차장으로 변합니다. 반면 REST는 여러 갈래의 국도를 달리는 소형 화물차와 같습니다. 속도는 느릴지언정 한 도로의 사고가 다른 화물의 도착을 막지는 않는 탄력적인 안정성을 확보합니다.
Summary
REST, GraphQL, gRPC는 서로 경쟁하는 기술이라기보다, 시스템의 목적과 성숙도에 따라 선택해야 할 서로 다른 ‘철학적 도구’입니다. REST는 웹의 보편성을 통해 외부 세계와의 연결을 담당하며, GraphQL은 프론트엔드의 파편화된 요구사항에 최적의 유연성을 제공합니다. 반면 gRPC는 엄격한 타입 안정성과 이진 효율성을 무기로 내부 마이크로서비스 간의 통신 부하를 혁신적으로 줄여줍니다. 아키텍트의 역할은 단순히 화려한 기술을 쫓는 것이 아니라, 현재 팀의 인프라와 배포 주기, 그리고 해결해야 할 병목 지점을 진단하여 가장 적절한 ‘결합도의 비용’을 지불하는 것입니다.
Selection Criteria
| 구분 | REST | GraphQL | gRPC |
|---|---|---|---|
| 주요 사용처 | Public API, 3rd-party 연동 | 복잡한 UI, 모바일 앱 | 내부 마이크로서비스(MSA) |
| 핵심 철학 | 리소스 중심 (상태 전송) | 클라이언트 중심 (데이터 요구) | 서비스 중심 (기능 호출) |
| 데이터 포맷 | JSON (텍스트 기반) | JSON (텍스트 기반) | Protobuf (이진 기반) |
| 통신 프로토콜 | HTTP/1.1 (보편적) | HTTP/1.1 (보편적) | HTTP/2 (멀티플렉싱) |
| 결합도 수준 | 느슨한 결합 (유연함) | 중간 (스키마 기반) | 강한 결합 (타입 안정성) |
| 최우선 이득 | 낮은 진입장벽, 캐싱 활용 | 라운드트립 감소, 생산성 | 고성능, 네트워크 최적화 |