[Web] REST API와 성숙도 모델
REST는 분산 하이퍼미디어 시스템을 위한 아키텍처 스타일입니다. 단순히 데이터 형식을 규정하는 것이 아니라, 시스템 구성 요소 간의 상호작용을 제약하여 장기적인 유지보수성과 확장성을 확보하는 데 목적이 있습니다. 로이 필딩(Roy Fielding)이 정의한 REST는 전 지구적 규모의 시스템이 수십 년간 붕괴하지 않고 진화할 수 있는 구조적 해답을 제시합니다.
🧩 REST API
REST는 특정 기술이나 프로토콜이 아닌 제약 조건들의 집합입니다. 시스템의 구성 요소가 이 제약들을 준수할 때마다 가시성(Visibility), 신뢰성(Reliability), 그리고 확장성(Scalability)이 향상됩니다.
Resource
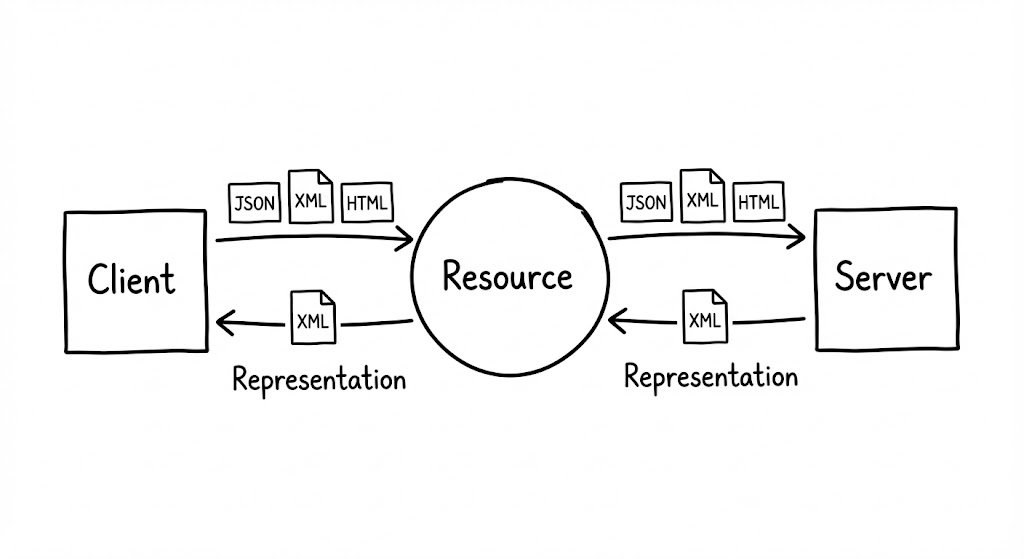
REST의 기본 단위는 리소스입니다. 리소스는 이름이 붙여질 수 있는 모든 정보의 추상화입니다. 핵심은 리소스가 특정 시점의 데이터 값이 아니라 개념적인 매핑 자체라는 점입니다.
예를 들어 특정 사용자의 주문 목록이라는 개념적 대상이 리소스가 됩니다. 실제 데이터는 변하더라도 리소스가 가리키는 대상의 본질은 변하지 않습니다. 설계 시 URI에 동사를 포함하여 행위를 기술하는 방식은 리소스의 고유한 식별 능력을 저해하므로 지양해야 합니다.
Representation
서버와 클라이언트는 리소스의 특정 시점 상태를 캡처한 표현을 주고받습니다. JSON이나 XML은 리소스를 나타내는 양식 중 하나일 뿐입니다. 클라이언트가 요청 헤더에 명시한 값에 따라 동일한 리소스라도 다양한 형식으로 전달될 수 있습니다.
표현의 구성 요소
리소스의 상태를 담은 데이터와 그 데이터를 설명하는 메타데이터의 결합체입니다. 하이퍼미디어를 통해 애플리케이션의 상태가 전이되는 방식이 중요하게 다뤄집니다.
Statelessness
무상태성 제약은 서버가 클라이언트의 이전 요청 문맥을 기억하지 않아야 함을 의미합니다. 모든 요청은 그 자체로 완결적이어야 하며 요청 처리에 필요한 모든 정보를 포함해야 합니다.
서버가 세션 상태를 유지하지 않으므로 특정 서버에 장애가 발생하더라도 다른 서버로 요청을 즉시 전달하여 처리할 수 있습니다. 이러한 특성은 서버가 자원을 점유하는 고착성을 제거하여 시스템의 수평적 확장(Scale-out)을 극대화하는 핵심 기제가 됩니다.
Uniform Interface
REST를 다른 아키텍처와 차별화하는 가장 강력한 제약은 일관된 인터페이스입니다. 이는 시스템 구성 요소 간의 상호작용을 단순화하고 결합도를 낮추는 역할을 합니다. 로이 필딩은 이를 위해 네 가지 세부 제약을 제시했습니다.
- 리소스 식별: URI를 통해 리소스를 명확히 구분한다.
- 표현을 통한 리소스 조작: 리소스의 표현을 서버에 전달하여 조작 의도를 명시한다.
- 자기 서술적 메시지: 메시지 내용만 보고도 이를 어떻게 처리할지 알 수 있어야 한다.
- HATEOAS: 응답 본문의 하이퍼링크를 통해 다음 상태로 가기 위한 경로를 동적으로 제공한다.
현대 API 설계에서 메시지의 자기 서술성과 HATEOAS가 누락되는 경우가 많습니다. 이 제약이 결여되면 클라이언트가 서버의 URI 구조를 미리 알고 있어야 하므로, 인터페이스 변경 시 클라이언트 코드도 함께 수정해야 하는 강한 결합 문제가 발생합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# GET /users/123/profile HTTP/1.1
# Host: api.example.com
# Accept: application/hal+json
HTTP/1.1 200 OK
Content-Type: application/hal+json; charset=utf-8
Cache-Control: public, max-age=3600
Vary: Accept-Encoding
{
"id": 123,
"name": "Andrej Karpathy",
"email": "andrej@example.com",
"role": "Engineer",
"_links": {
"self": { "href": "/users/123/profile" },
"orders": { "href": "/users/123/orders" },
"update": { "href": "/users/123/profile", "method": "PATCH" }
}
}
🧩 Maturity Model
리처드슨 성숙도 모델(Richardson Maturity Model)은 REST의 제약 조건을 단계별로 나누어 시스템의 성숙도를 측정하는 지표입니다. 이는 단순히 기술적인 등급을 매기는 것이 아니라, 서비스가 복잡해짐에 따라 발생하는 엔드포인트 관리 문제를 프로토콜의 표준 규약을 통해 어떻게 해결할 것인지에 대한 단계적 접근법을 제시합니다.
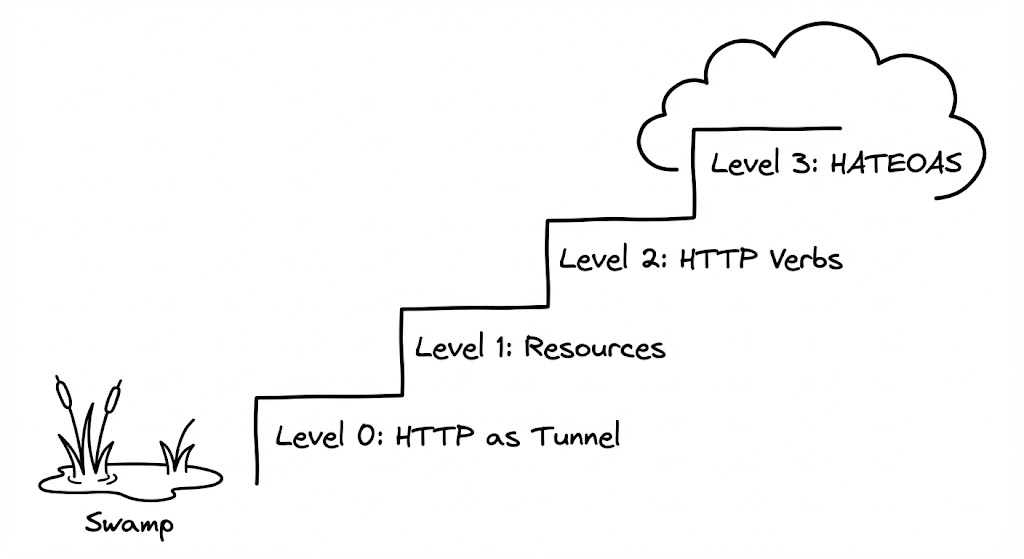
Level 0 to 1: 리소스의 발견과 식별
레벨 0은 HTTP를 단순히 데이터를 주고받기 위한 전송 터널로만 사용하는 단계입니다. 하나의 엔드포인트(예: /api/service)로 모든 요청을 보내며, 수행할 동작은 요청 본문에 기술된 함수 이름에 의존합니다. 이는 전형적인 원격 프로시저 호출(RPC) 스타일로, 클라이언트가 서버 내부의 함수 명세를 정확히 알아야 하는 강한 결합을 유발합니다.
레벨 1로 진화하면서 ‘리소스’라는 개념이 도입됩니다. 이제 클라이언트는 거대한 서비스 전체가 아니라 개별적으로 식별되는 리소스와 통신합니다. /users, /orders/1과 같이 명사 형태의 경로가 나타나며 비즈니스 로직이 리소스 단위로 분할됩니다. 다만 이 단계에서도 조작 방식은 여전히 POST 메서드 하나에 의존하는 경향이 있습니다.
Level 2: HTTP 메서드를 통한 규약의 완성
레벨 2는 대다수의 현대 API가 지향하는 지점입니다. HTTP 표준 메서드인 GET, POST, PUT, DELETE를 각각의 목적에 맞게 사용합니다. 이 단계의 핵심은 안전성(Safe)과 멱등성(Idempotency)이라는 프로토콜 수준의 약속을 활용하는 데 있습니다.
네트워크 타임아웃 등으로 인해 재시도(Retry)가 필요한 분산 시스템에서 멱등 메서드인 GET이나 PUT을 올바르게 구현하면 시스템의 부작용 없이 안전하게 재요청을 수행할 수 있습니다. 반면 모든 처리를 POST로 수행하는 이전 단계에서는 재시도가 데이터 오염(예: 중복 결제)으로 이어질 위험이 큽니다. 또한 HTTP 상태 코드를 통해 응답 본문을 확인하지 않고도 요청 결과에 대한 가시성을 즉각적으로 확보할 수 있습니다.
Level 3: 하이퍼미디어를 통한 엔진으로서의 상태 제어 (HATEOAS)
성숙도의 정점인 레벨 3은 응답 본문에 현재 리소스의 데이터뿐만 아니라 클라이언트가 다음에 수행할 수 있는 행동(Link) 정보를 포함합니다.
클라이언트는 특정 비즈니스 흐름을 처리하기 위해 어떤 URL로 요청을 보내야 할지 미리 알 필요가 없습니다. API 응답에서 제공하는 링크를 따라가며 다음 상태로 전이하면 되기 때문입니다. 이는 서버가 경로 구조를 변경하더라도 클라이언트 코드를 수정할 필요가 없게 만드는 결합도 해소의 핵심 장치가 됩니다.
HATEOAS 응답의 구조적 차이
단순 데이터를 반환하는 것을 넘어, 응답 본문에
_links나rel과 같은 메타데이터를 포함시켜 애플리케이션의 상태 전이를 가이드합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
// Level 0: The Swamp of POX (RPC 스타일)
// POST /userService
{
"function": "cancelOrder",
"orderId": "ORD-99",
"reason": "changed mind"
}
// --------------------------------------------------
// Level 3: HATEOAS (HAL 표준 적용)
// GET /orders/99
{
"orderId": "ORD-99",
"status": "AWAITING_PAYMENT",
"amount": 150.00,
"currency": "USD",
"_links": {
"self": { "href": "/orders/99" },
"payment": { "href": "/orders/99/payment" },
"cancel": { "href": "/orders/99/cancellation" }
}
}
HATEOAS Trade-off
로이 필딩은 하이퍼미디어가 애플리케이션 상태의 엔진으로 동작하지 않는다면 그것은 REST가 아니라고 강조했습니다. 하지만 실제 산업 현장에서 레벨 3을 달성한 API는 드뭅니다. 이는 HATEOAS가 제공하는 아키텍처적 이점과 현실적인 구현 비용 사이의 간극 때문입니다.
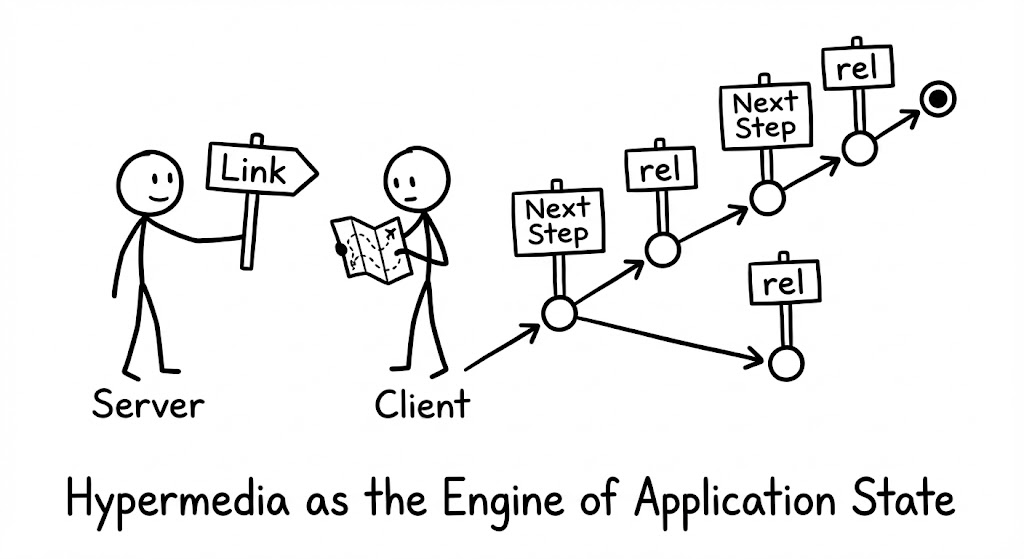
클라이언트 결합도 해제
HATEOAS를 적용하면 클라이언트와 서버 사이의 완전한 디커플링이 가능해집니다. 일반적인 설계에서 클라이언트는 주문 취소를 위해 특정 URL 구조를 코드에 하드코딩해야 하며, 이는 서버 구조 변경 시 클라이언트 배포를 강제합니다.
반면 HATEOAS 기반 API에서 서버는 응답 본문에 현재 상태에서 가능한 다음 행동들을 링크 형식으로 제공합니다. 예를 들어 주문 취소가 배송 시작 전이라는 특정 조건에서만 가능하다면, 서버는 해당 조건이 충족될 때만 취소 링크를 포함합니다. 클라이언트는 비즈니스 로직을 중복 구현할 필요 없이 링크의 존재 여부만 확인하면 되며, 서버는 클라이언트 수정 없이 인터페이스를 유연하게 진화시킬 수 있습니다.
오버헤드와 구현 복잡성
이러한 이점에도 불구하고 HATEOAS 도입에는 성능과 복잡성이라는 기회비용이 따릅니다.
- 네트워크 오버헤드: 매 응답마다 링크 메타데이터를 포함하므로 페이로드 크기가 커집니다. 대역폭이 제한적인 환경에서는 레이턴시를 증가시키는 요인이 됩니다.
- 클라이언트 구현 난이도: 클라이언트가 단순히 데이터를 파싱하는 것을 넘어 링크를 해석하고 탐색하는 역할을 수행해야 하므로 코드 복잡도가 높아집니다.
- 문서화의 문제: 링크를 동적으로 제공하더라도 각 관계(Relation)가 의미하는 바를 설명하는 메타데이터 정의가 별도로 필요하며, 이는 기존 API 문서화 도구들과 매끄럽게 호환되지 않는 경우가 많습니다.
따라서 서버와 클라이언트를 직접 통제할 수 있는 환경에서는 이러한 복잡성을 감수하기보다 실용적인 관점에서 레벨 2에 머무는 경우가 많습니다.
HATEOAS 도입 범위의 한정
모든 API에 적용하기보다 비즈니스 흐름이 복잡하고 상태 전이가 잦은 핵심 도메인에 한정하여 부분적으로 도입하는 것이 합리적인 전략일 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
// GET /api/v1/orders/ORD-2026-99
{
"orderId": "ORD-2026-99",
"status": "AWAITING_PAYMENT",
"customer": "Andrej Karpathy",
"items": [
{ "name": "GeForce RTX 5090", "quantity": 1, "price": 1999.00 }
],
"totalAmount": 1999.00,
"currency": "USD",
"createdAt": "2026-01-10T15:30:00Z",
"_links": {
"self": { "href": "/api/v1/orders/ORD-2026-99" },
"payment": {
"href": "/api/v1/payments/pay",
"method": "POST",
"title": "결제하기"
},
"cancel": {
"href": "/api/v1/orders/ORD-2026-99/cancellation",
"method": "DELETE",
"title": "주문 취소"
},
"help": { "href": "https://docs.example.com/api/orders/status" }
}
}
Idempotency Strategy
분산 시스템에서 네트워크는 언제나 실패할 수 있다는 가정이 필요합니다. 요청의 성공 여부를 확신할 수 없는 환경에서 시스템 정합성을 유지하기 위한 핵심 개념이 멱등성(Idempotency)입니다. 멱등성은 동일한 요청을 여러 번 수행하더라도 서버의 상태가 처음 한 번 수행했을 때와 동일하게 유지되는 성질을 의미하며, 이는 시스템의 안정성을 보장하는 생존 전략입니다.
멱등성 키 적용
HTTP 명세상 GET, PUT, DELETE는 기본적으로 멱등성을 가집니다. 하지만 비즈니스 로직이 복잡해지면 프로토콜의 명세만으로 정합성을 보장하기 어렵습니다. 예를 들어 PUT 요청 중 네트워크 타임아웃이 발생하면, 클라이언트는 요청이 서버에 도달해 처리되었는지 아니면 전달조차 되지 않았는지 판단할 수 없습니다.
이를 해결하기 위해 Idempotency-Key와 같은 고유 식별자를 헤더에 포함하는 방식을 사용합니다. 클라이언트가 요청마다 UUID 등의 고유 키를 생성해 보내면, 서버는 이 키를 저장소에 기록합니다. 이후 동일한 키로 요청이 다시 들어오면 로직을 재실행하는 대신 기존에 저장된 응답을 반환합니다. 이는 리소스 생성 작업에서도 중복 발생 없이 안전한 재시도를 가능하게 합니다.
중복 요청 처리
재시도는 클라이언트 입장에서 성공 가능성을 높이는 수단이지만, 서버 자원을 추가로 소모하게 만듭니다. 특히 마이크로서비스 아키텍처와 같이 여러 서비스가 체인 형태로 연결된 구조에서는 재시도가 하위 시스템으로 전달되며 부하가 기하급수적으로 증폭되는 리스크가 있습니다.
멱등성이 담보되지 않은 상태에서 이러한 재시도가 반복되면 데이터 오염과 시스템 마비가 동시에 발생할 수 있습니다. 따라서 멱등성 설계는 지수 백오프(Exponential Backoff)와 지터(Jitter)를 적용한 재시도 전략이 시스템을 붕괴시키지 않도록 방어하는 역할을 합니다. 엔지니어는 비즈니스 로직과 프로토콜 처리가 맞물리는 지점에서 상태 변화를 원자적(Atomic)으로 관리해야 합니다.
멱등성 설계의 골든 룰
읽기 전용 API는 자연스럽게 멱등하지만, 리소스 생성(POST)이나 복잡한 상태 전이는 명시적인 토큰 메커니즘이 필요합니다. 멱등성은 클라이언트가 시스템 부작용을 걱정하지 않고 재시도할 수 있는 권리를 부여합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
@PostMapping("/v1/orders")
public ResponseEntity<OrderResponse> createOrder(
@RequestHeader(value = "Idempotency-Key", required = false) String idempotencyKey,
@RequestBody OrderRequest request
) {
// 1. 멱등성 키가 없는 경우: 일반적인 비즈니스 로직 수행
if (idempotencyKey == null || idempotencyKey.isBlank()) {
return ResponseEntity.ok(orderService.process(request));
}
// 2. 저장소(Redis 등)에서 기존 처리 내역 확인 (Atomic Look-up)
// 이미 완료된 요청은 중복 실행 없이 즉시 반환함
IdempotencyRecord cachedRecord = idempotencyRepository.findByKey(idempotencyKey);
if (cachedRecord != null) {
if (cachedRecord.isProcessing()) {
// 동일 키로 현재 처리 중인 요청이 있는 경우 409 Conflict 반환
return ResponseEntity.status(HttpStatus.CONFLICT).build();
}
// 저장된 응답 객체를 반환 (Payload와 상태 코드 복원)
return ResponseEntity.status(cachedRecord.getStatusCode())
.body(cachedRecord.getResponsePayload());
}
// 3. 멱등성 레코드 생성 (처리 중 상태로 표시하여 Race Condition 방지)
idempotencyRepository.save(new IdempotencyRecord(idempotencyKey, Status.PROCESSING));
try {
// 4. 실제 비즈니스 로직 수행 (결제, 리소스 생성 등 Side-effects 발생 지점)
OrderResponse response = orderService.process(request);
// 5. 처리 결과 및 응답 상태 저장 (24시간 등 TTL 설정 권장)
idempotencyRepository.updateResult(idempotencyKey, response, HttpStatus.OK);
return ResponseEntity.ok(response);
} catch (Exception e) {
// 6. 예외 발생 시 멱등성 레코드 삭제 또는 실패 상태 기록
// 클라이언트가 이후에 동일한 키로 안전하게 재시도할 수 있도록 보장함
idempotencyRepository.deleteByKey(idempotencyKey);
throw e;
}
}
HTTP Semantics Pollution
모든 응답을 200 OK로 반환하면서 본문 내부 메시지로만 성공/실패를 구분하는 방식은 HTTP를 단순한 전송 도구로 전락시키는 설계입니다. 이는 로이 필딩이 강조한 ‘자기 서술적 메시지’ 원칙에 어긋나며, 캐시 프록시나 로드 밸런서 등 네트워크 중간 계층의 효율적인 동작을 방해합니다.
200 OK 오용 문제
HTTP 상태 코드는 전 지구적 네트워크가 요청의 결과를 이해하는 공용어입니다. 표준 상태 코드는 단순히 성공과 실패를 알리는 것을 넘어 요청의 재시도 가능 여부까지 함축합니다.
- 4xx (Client Error): 요청 자체에 문제가 있으므로 재시도해도 결과가 달라지지 않음을 의미합니다.
- 5xx (Server Error): 일시적인 장애일 가능성이 있으므로 나중에 다시 시도하면 성공할 수 있음을 의미합니다.
모든 응답을 200 OK로 통일하면 표준 네트워크 장비나 라이브러리가 요청의 성격을 판단할 수 없게 되어 시스템의 가시성과 복구 능력이 저하됩니다.
에러 계층 분리
성숙한 API 설계는 프로토콜 수준의 실패와 애플리케이션 수준의 비즈니스 실패를 격리합니다. 상태 코드는 리소스를 찾지 못한 경우(404), 권한이 없는 경우(403) 등 의미론적 표준에 맞춰 사용해야 합니다.
구체적인 비즈니스 실패 사유(예: 잔액 부족, 재고 없음)는 응답 본문의 별도 필드(예: errorCode)로 정의하는 것이 좋습니다. 이를 통해 클라이언트는 네트워크 연결이나 인증 같은 프로토콜 문제와 비즈니스 로직상의 문제를 명확히 구분하여 처리할 수 있습니다.
에러 처리의 황금률
HTTP 상태 코드는 ‘요청 처리의 결과’를 기술하고, 응답 본문의 에러 객체는 ‘실패의 구체적 이유’를 기술해야 합니다. 이 둘의 역할을 명확히 구분할 때 API의 범용성이 확보됩니다.
Summary
REST API와 성숙도 모델은 분산 시스템의 복잡성을 관리하고 클라이언트와 서버 간의 독립적 진화를 보장하기 위한 아키텍처적 장치입니다. 리소스 중심의 설계와 멱등성을 올바르게 활용할 때, 시스템은 네트워크 실패 상황에서도 회복 탄력성(Resilience)을 확보할 수 있습니다. 표준 규약을 준수하는 것은 대규모 시스템의 유지보수 비용을 낮추고 예측 가능성을 높이는 핵심적인 투자입니다.