[JVM Internal] JVM Memory Layout
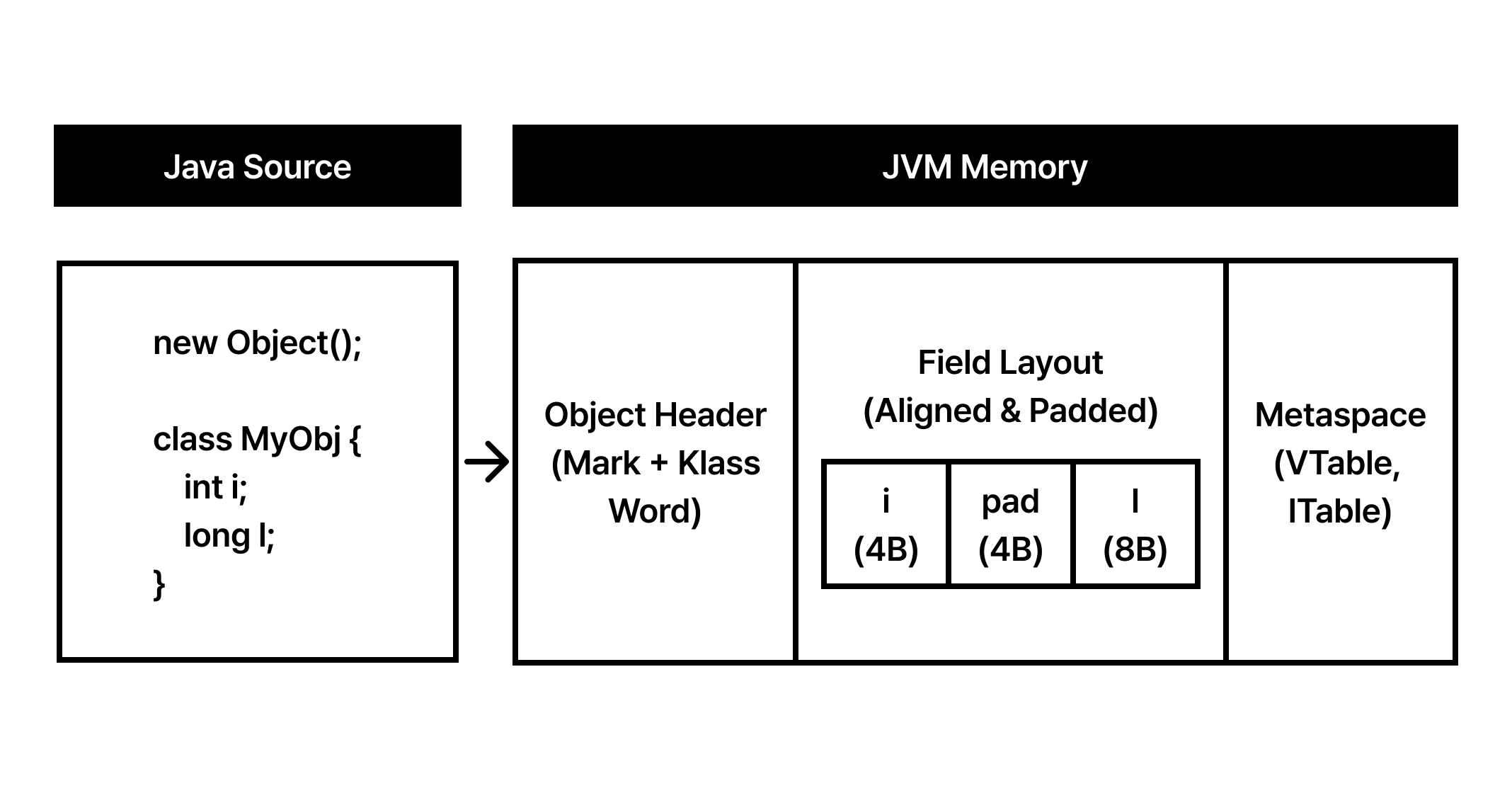
자바 개발자가 new 키워드를 호출하는 순간, 추상적인 소스 코드는 운영체제가 관리하는 물리적인 메모리 영역으로 하강합니다. 우리는 흔히 객체를 ‘데이터와 행위의 집합’으로 정의하지만, JVM 실행 엔진의 관점에서 객체는 철저하게 계산된 바이트의 연속(Sequence of Bytes)일 뿐입니다.
자바가 고성능 시스템 언어인 C++로 작성된 HotSpot JVM 위에서 돌아간다는 점을 상기해 보십시오. JVM은 가비지 컬렉션의 효율성을 높이고, 멀티스레드 환경에서 락(Lock) 경합을 최소화하며, CPU 캐시 라인을 최적으로 활용하기 위해 객체의 레이아웃을 바이트 단위로 정밀하게 설계했습니다. 이 설계의 정수가 바로 모든 객체의 최상단에 위치하는 ‘헤더’와, 데이터를 정렬하는 ‘패딩’ 메커니즘입니다. 이제 우리는 추상화의 베일을 벗기고, 메모리 덤프 속에 숨겨진 0과 1의 규칙을 추적할 것입니다.
🧩 Object Header
JVM 메모리 세상에서 모든 객체 인스턴스는 예외 없이 자신만의 ‘신분증’을 머리에 이고 태어납니다. 이를 Object Header라고 부릅니다. 64비트 HotSpot JVM 환경에서 이 헤더는 일반적으로 12바이트에서 16바이트를 차지하며, 객체의 상태를 증명하는 두 가지 핵심 요소로 구성됩니다.
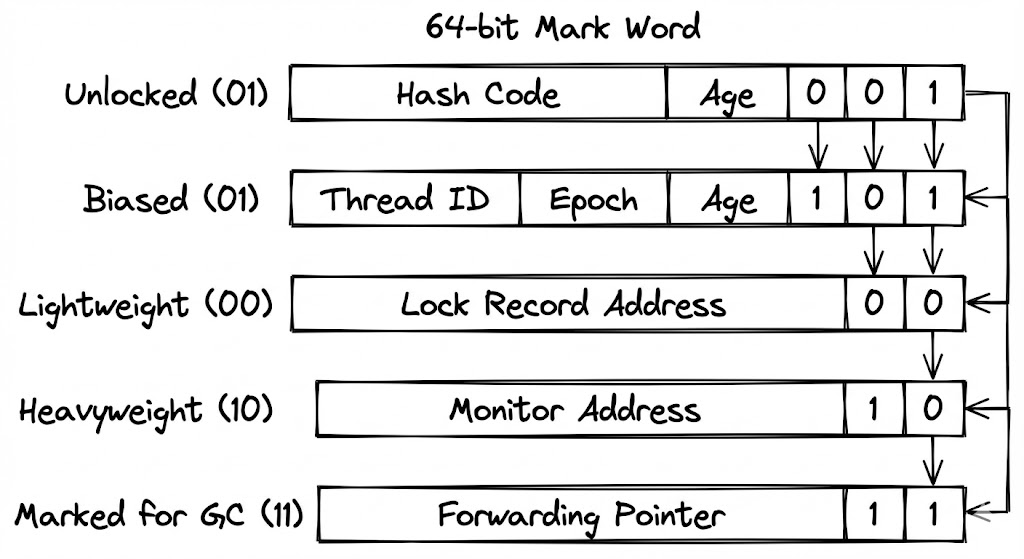
Mark Word
Mark Word는 객체의 생애 주기 동안 변하는 동적인 상태를 기록하는 8바이트(64비트) 공간입니다. JVM 엔지니어들은 이 한정된 공간을 극한으로 활용하기 위해 비트 마스킹 기법을 동원했습니다.
Mark Word에는 크게 네 가지 정보가 담깁니다.
- Identity HashCode: 객체의 고유 해시값.
System.identityHashCode()호출 시 생성되어 기록됩니다. - GC Age: 가비지 컬렉션의 서바이버 영역에서 살아남은 횟수(최대 15).
- Lock Information: 현재 이 객체를 어떤 스레드가 점유하고 있는지, 어떤 수준의 락(Biased, Lightweight, Heavyweight)이 걸려 있는지를 나타내는 비트 패턴.
- Epoch: 편향 락(Biased Locking)의 유효성을 검증하기 위한 타임스탬프.
해시코드 생성의 트레이드오프
객체가 생성되자마자 해시코드가 Mark Word에 기록되는 것은 아닙니다. 실제 호출이 발생하는 순간에만 계산되어 기록되는데, 만약 객체가 락이 걸린 상태에서 해시코드 호출이 발생하면 JVM은 더 복잡한 방식으로 상태를 관리해야 하므로 성능에 미세한 영향을 줄 수 있습니다.
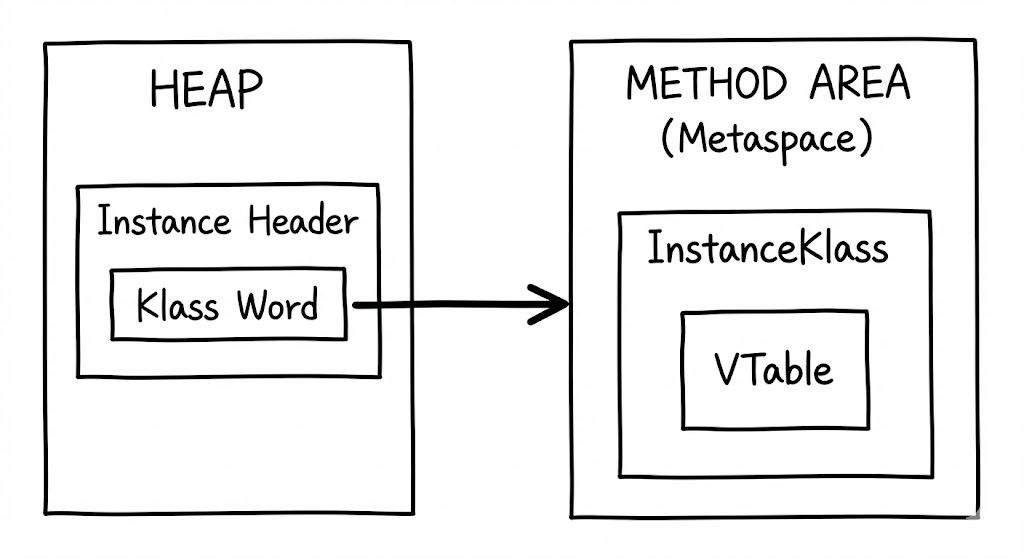
Klass Word
Mark Word가 ‘이 객체가 현재 어떤 상태인가’를 말해준다면, Klass Word는 ‘이 객체는 무엇인가’를 말해줍니다. 이는 해당 인스턴스의 설계도인 Klass 구조체(Metaspace에 위치)를 가리키는 C++ 포인터입니다.
JVM은 이 포인터를 통해 런타임에 객체의 타입을 확인하고, 가상 메서드 테이블(VTable)에 접근하여 다형성을 구현합니다. 여기서 주목할 점은 Compressed OOPs 기술입니다. 64비트 환경에서 포인터는 원래 8바이트여야 하지만, JVM은 32GB 이하의 힙 메모리 환경에서 이 포인터를 4바이트로 압축하여 저장합니다. 이를 통해 헤더 크기를 16바이트에서 12바이트로 줄여 메모리 효율을 극대화합니다.
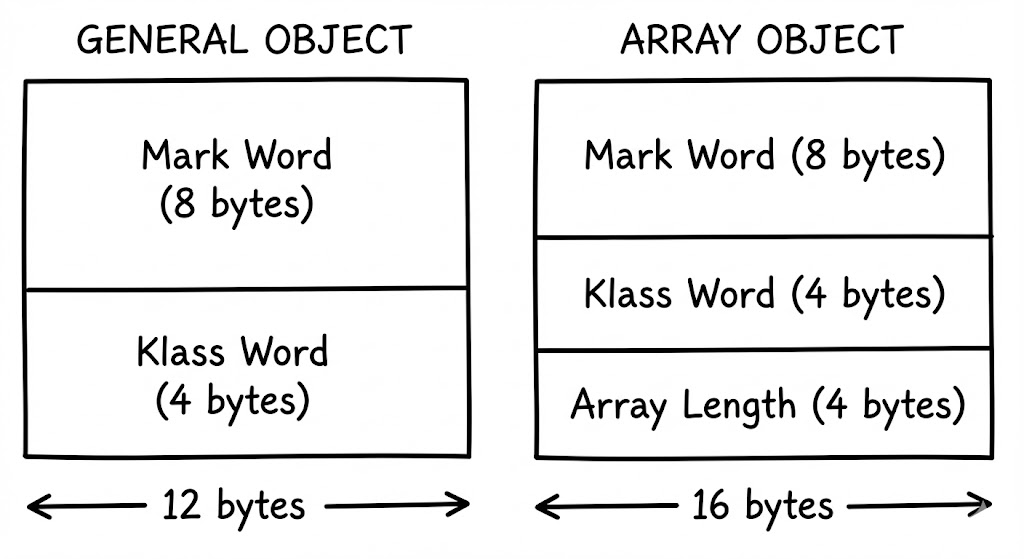
Array Length
자바의 배열(Array)도 객체이지만, 일반 객체와 결정적인 차이가 있습니다. 바로 ‘길이’ 정보입니다. 일반 객체는 클래스 설계도에 필드 구성이 고정되어 있지만, 배열은 생성 시점에 길이가 결정되므로 이를 별도로 저장해야 합니다. 따라서 배열 인스턴스의 헤더에는 Mark Word와 Klass Word 뒤에 4바이트의 Array Length 필드가 추가로 붙습니다. 결과적으로 배열의 헤더는 일반 객체보다 4바이트 더 큰 구조를 갖게 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
import org.openjdk.jol.info.ClassLayout;
/**
* JVM 객체 레이아웃 및 락 상태 변화 관찰
*/
public class ObjectLayoutAnalysis {
public static void main(String[] args) {
// 1. 일반 객체(Object)의 헤더 구조 분석 (Mark Word + Klass Word)
Object plainObject = new Object();
System.out.println("=== 1. 일반 객체의 레이아웃 (12-16 바이트) ===");
System.out.println(ClassLayout.parseInstance(plainObject).toPrintable());
// 2. 배열 객체의 헤더 확장 (Array Length 필드 추가)
int[] intArray = new int[0];
System.out.println("=== 2. 배열 객체의 레이아웃 (Array Length 포함) ===");
System.out.println(ClassLayout.parseInstance(intArray).toPrintable());
// 3. Mark Word의 동적 변화 관찰
Object lockObject = new Object();
// [상태 A] 초기 상태 (Unlocked)
System.out.println("=== 3-A. 초기 상태의 Mark Word ===");
System.out.println(ClassLayout.parseInstance(lockObject).toPrintable());
// [상태 B] Identity HashCode 생성 (Mark Word에 해시코드 기록)
lockObject.hashCode();
System.out.println("=== 3-B. hashCode() 호출 후 (비트 패턴 변화) ===");
System.out.println(ClassLayout.parseInstance(lockObject).toPrintable());
// [상태 C] 락 경합 발생 (Lock Information 기록)
synchronized (lockObject) {
System.out.println("=== 3-C. synchronized 블록 내부 (Lock 상태) ===");
System.out.println(ClassLayout.parseInstance(lockObject).toPrintable());
}
}
}
🧩 Field Layout
객체의 헤더가 신분증이라면, 필드 레이아웃은 그 신분증 뒤에 붙는 실제 데이터 본문입니다. 하지만 JVM은 이 데이터를 단순히 선언된 순서대로 나열하지 않습니다. 여기에는 ‘메모리 정렬(Alignment)’과 ‘공간 밀도(Density)’라는 두 마리 토끼를 잡기 위한 고도의 최적화 알고리즘이 개입합니다.
Primitive Types
자바의 기본형 타입들은 메모리 위에서 저마다의 확고한 영토를 가집니다. boolean과 byte는 1바이트, char와 short는 2바이트, int와 float는 4바이트, 그리고 long과 double은 8바이트를 점유합니다. 객체 참조 변수(Reference)의 경우, 앞서 언급한 Compressed OOPs 적용 여부에 따라 4바이트 또는 8바이트가 할당됩니다.
이때 중요한 개념이 오프셋(Offset)입니다. 오프셋은 객체의 시작 지점(헤더의 0번 바이트)으로부터 특정 필드가 위치한 지점까지의 거리를 의미합니다. JVM은 실행 효율을 위해 이 오프셋을 특정 배수 단위로 맞추려는 강박을 가지고 있습니다.
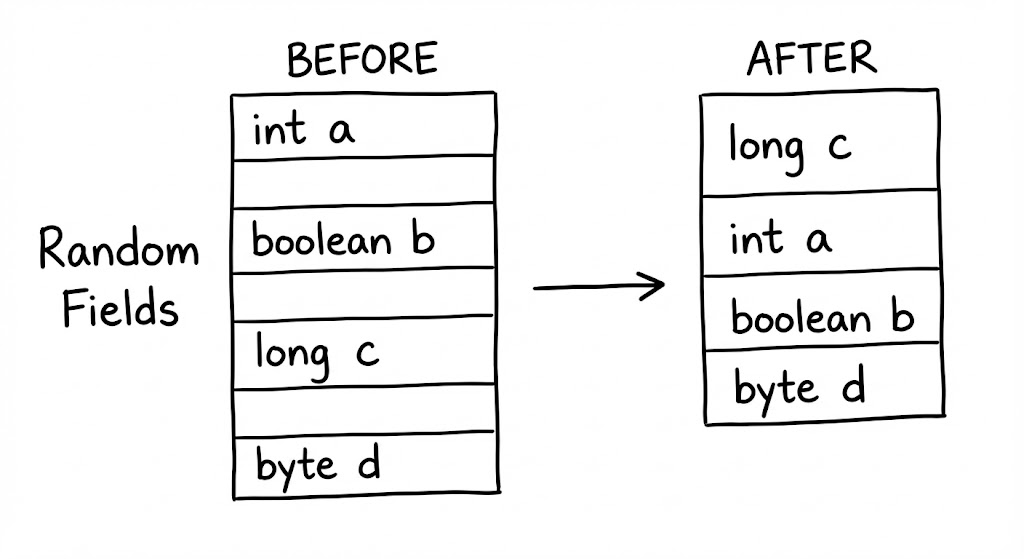
Field Reordering
개발자가 클래스에 필드를 byte, long, int 순으로 선언했다고 가정해 봅시다. 만약 이 순서 그대로 메모리에 배치한다면, byte 뒤에 8바이트인 long을 맞추기 위해 무의미한 빈 공간(Padding)이 대량으로 발생하게 됩니다.
JVM은 이를 방지하기 위해 필드 선언 순서를 무시하고 ‘크기 순 재배치’ 전략을 취합니다. 일반적으로 long/double -> int/float -> short/char -> byte/boolean -> references 순으로 모아서 배치함으로써, 필드 사이사이에 끼어드는 패딩을 최소화하는 ‘바이너리 테트리스’를 수행합니다.
Alignment Padding
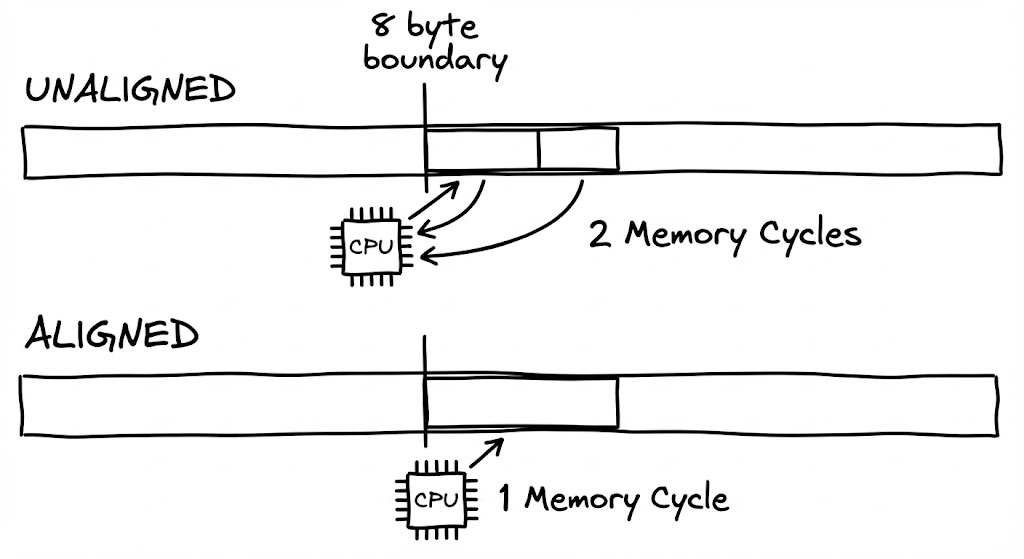
왜 JVM은 굳이 복잡한 계산을 거쳐 데이터를 정렬할까요? 이는 현대 CPU의 메모리 읽기 메커니즘 때문입니다. 64비트 CPU는 메모리에서 데이터를 읽어올 때 8바이트(64비트) 단위로 읽는 것이 가장 빠릅니다. 만약 8바이트 크기의 long 데이터가 4번 바이트부터 12번 바이트에 걸쳐 있다면, CPU는 이 데이터를 읽기 위해 메모리에 두 번 접근해야 하는 비효율이 발생합니다.
이를 방지하기 위해 JVM은 두 가지 패딩을 삽입합니다.
- Internal Padding: 필드와 필드 사이를 메워 다음 필드가 자신의 크기 배수 위치에서 시작하게 함.
- External Padding: 객체의 전체 크기를 8의 배수로 맞춤. 객체 크기가 20바이트라면 뒤에 4바이트를 추가해 24바이트로 만듭니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
import org.openjdk.jol.info.ClassLayout;
/**
* JVM의 필드 재배치(Field Reordering)와 패딩(Padding) 관찰
* * 포인트: JVM은 선언 순서를 무시하고 '헤더 빈틈 메우기'와 '정렬'을 우선합니다.
*/
public class FieldLayoutAnalysis {
// 최적화가 없다면 타입 사이사이에 막대한 패딩이 발생해야 함
static class SuboptimalLayout {
// [개발자의 선언 순서]
boolean a; // 1 byte
long b; // 8 bytes
int c; // 4 bytes
byte d; // 1 byte
Object e; // 4 bytes (Compressed OOPs 적용 시)
}
public static void main(String[] args) {
System.out.println("=== [SuboptimalLayout 클래스의 물리적 배치 분석] ===");
// 클래스의 레이아웃 정보 출력
System.out.println(ClassLayout.parseClass(SuboptimalLayout.class).toPrintable());
/*
* 관전 포인트:
* 1. Reordering: 선언 순서(a, b, c, d, e)가 유지되는가,
* 아니면 헤더가 끝나는 지점의 '자투리 공간'을 먼저 채우는가?
* 2. Internal Padding: 필드 사이를 메우는 빈 공간이 있는가?
* 3. External Padding (Loss): 전체 크기를 8의 배수로 맞추기 위해
* 마지막에 추가된 공간이 얼마인가?
*/
}
}
🧩 Virtual Method Table
자바에서 parent.method()를 호출했을 때, 런타임에 실제 인스턴스의 타입에 맞는 메서드가 실행되는 마법은 Virtual Method Table(vtable)이라는 정교한 주소록 덕분입니다. 이는 단순히 논리적인 개념이 아니라, JVM의 메타데이터 영역(Metaspace)에 존재하는 실제 포인터 배열입니다.
상속과 메모리 오버레이
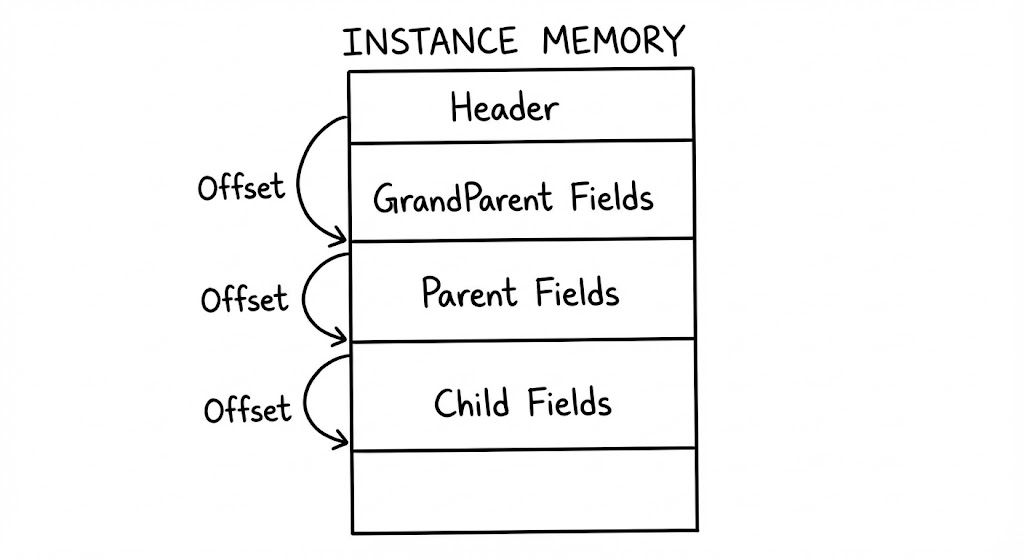
객체가 상속될 때, 메모리 레이아웃은 부모의 데이터를 바탕으로 자식의 데이터를 덧붙이는 선형 확장 구조를 가집니다. 자식 인스턴스가 생성되면 가장 먼저 부모 클래스에 정의된 필드들이 헤더 바로 뒤에 배치되고, 그 뒤를 이어 자식 클래스의 고유 필드들이 자리를 잡습니다.
이 구조 덕분에 JVM은 자식 객체를 부모 타입으로 캐스팅하더라도, 부모 필드의 오프셋(시작 지점으로부터의 거리)이 변하지 않는다는 것을 보장할 수 있습니다. 즉, 어떤 타입으로 보든 ‘부모로부터 물려받은 데이터’는 항상 같은 자리에 위치합니다.
VTable
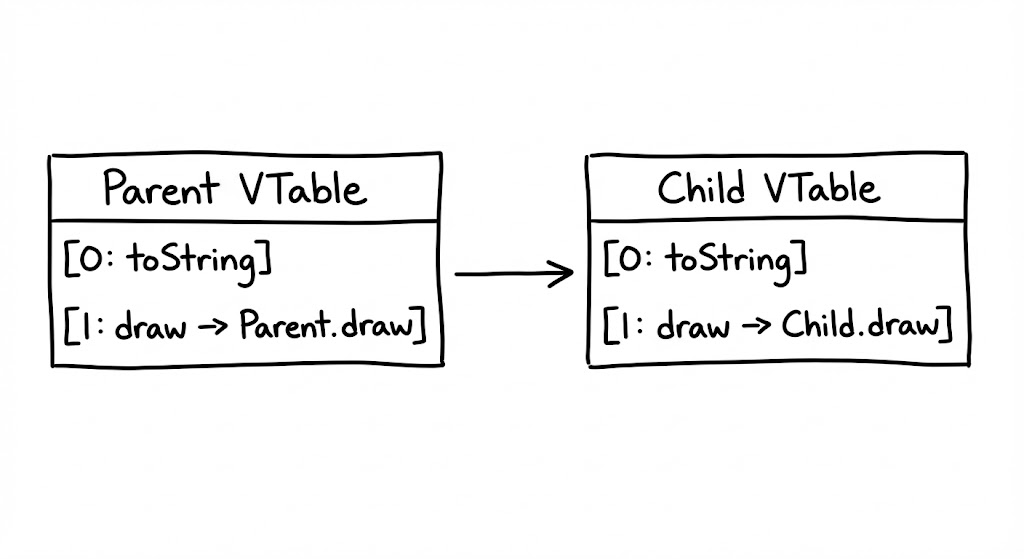
JVM은 클래스를 로딩할 때 해당 클래스가 가진 모든 ‘가상 메서드(가시성이 확보된 인스턴스 메서드)’의 엔트리 포인트를 나열한 vtable을 생성합니다. 상속 관계에서 이 테이블은 다음과 같은 순서로 조립됩니다.
- 부모의 복제: 자식 클래스의 vtable은 부모 클래스의 vtable 내용을 그대로 복사하여 시작합니다.
- 오버라이딩(Overriding): 자식 클래스가 부모의 메서드를 재정의했다면, 복사해온 vtable의 해당 슬롯 주소를 자식이 새로 구현한 메서드의 주소로 갈아 끼웁니다.
- 신규 메서드 추가: 자식 클래스에서만 정의된 새로운 메서드들은 테이블의 가장 마지막 슬롯 뒤에 추가됩니다.
이 메커니즘 덕분에 invokevirtual 명령어가 실행될 때, JVM은 인스턴스의 헤더(Klass Word)를 통해 vtable에 접근한 뒤, 컴파일 타임에 결정된 ‘고정된 인덱스’의 주소값으로 점프하기만 하면 됩니다. 이것이 자바 다형성이 런타임에 매우 빠르게 동작하는 비결입니다.
vtable의 위치와 참조
엄밀히 말하면 vtable은 힙에 있는 ‘객체 인스턴스’ 내부에 매번 생성되지 않습니다. 대신 Metaspace의
InstanceKlass구조체 내부에 위치하며, 모든 인스턴스는 헤더의 Klass Word를 통해 이 단 하나의 공유 테이블을 참조합니다. 이는 수백만 개의 인스턴스가 생성되어도 메서드 주소록은 클래스당 하나만 존재하게 하여 메모리를 절약하는 설계입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
import org.openjdk.jol.info.ClassLayout;
/**
* 상속 관계에서의 필드 선형 확장 및 vtable 논리 구조 시뮬레이션
*/
public class InheritanceVTableAnalysis {
static class A {
long aField;
void m1() { System.out.println("A.m1()"); }
void m2() { System.out.println("A.m2()"); }
}
static class B extends A {
int bField;
@Override
void m1() { System.out.println("B.m1() - Overridden"); }
void m3() { System.out.println("B.m3()"); }
}
static class C extends B {
byte cField;
@Override
void m3() { System.out.println("C.m3() - Overridden"); }
void m4() { System.out.println("C.m4()"); }
}
public static void main(String[] args) {
C instanceC = new C();
// 1. 물리적 필드 배치 확인 (선형 확장)
System.out.println("=== [Class C의 메모리 레이아웃: 부모 필드부터 쌓이는 구조] ===");
System.out.println(ClassLayout.parseInstance(instanceC).toPrintable());
// 2. 다형성 호출 시뮬레이션 (vtable 기반)
System.out.println("=== [다형성 호출 시 런타임 메서드 바인딩] ===");
A polyA = instanceC; // C 인스턴스를 A 타입으로 참조
System.out.print("polyA.m1() 호출 결과: ");
polyA.m1(); // vtable 인덱스 0번(예시) 추적 -> B.m1() 실행
System.out.print("polyA.m2() 호출 결과: ");
polyA.m2(); // vtable 인덱스 1번(예시) 추적 -> A.m2() 실행 (부모 것 유지)
}
}
🧩 Interface Method Table
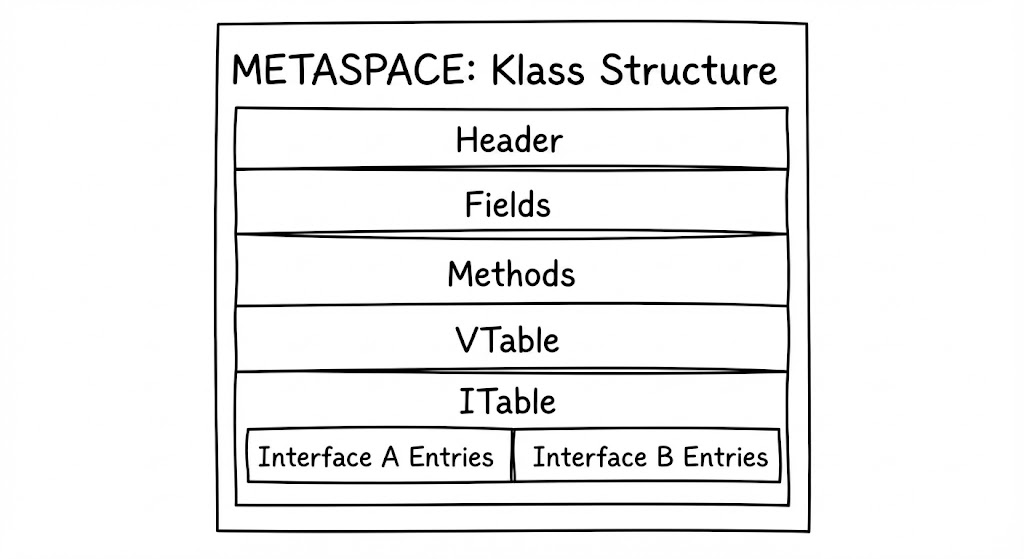
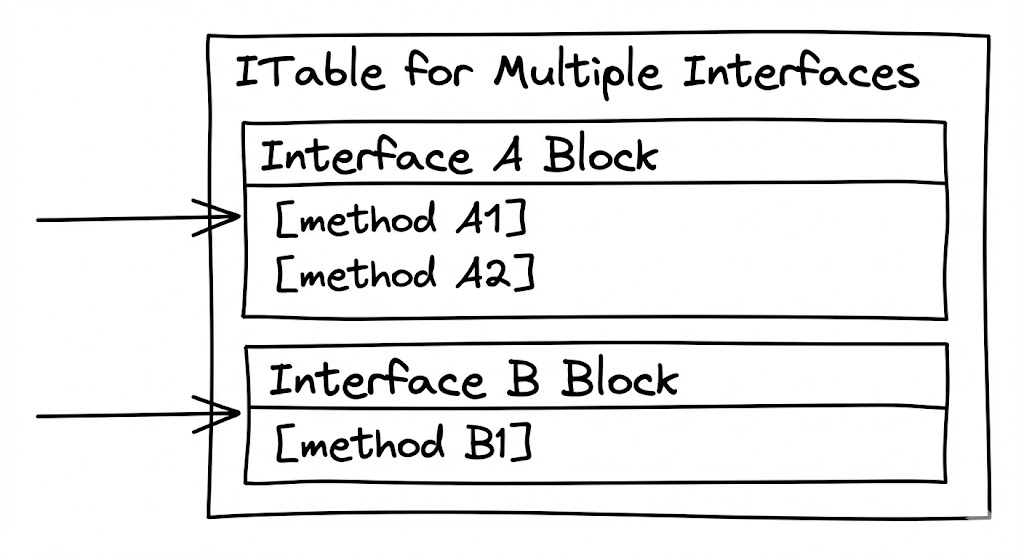
자바의 인터페이스는 클래스 계층 구조에 구애받지 않는 유연함을 제공하지만, 이를 지원하기 위한 JVM의 뒷면은 훨씬 복잡해집니다. VTable은 선형적인 상속 관계를 전제로 ‘고정된 인덱스’를 사용해 메서드를 찾지만, 인터페이스는 어떤 클래스가 이를 구현할지 알 수 없기에 고정된 인덱스를 부여할 수 없습니다. 이 문제를 해결하는 장치가 바로 Interface Method Table(ITable)입니다.
ITable
VTable 호출(invokevirtual)이 “VTable의 5번 슬롯으로 가서 실행해”라고 명령한다면, 인터페이스 호출(invokeinterface)은 “이 객체가 구현한 인터페이스 목록 중 ‘Comparable’을 찾고, 그 안에서 ‘compareTo’ 메서드를 찾아 실행해”라는 과정을 거칩니다.
ITable은 크게 두 부분으로 나뉩니다.
- ITable Offset Entry: 해당 클래스가 구현한 각 인터페이스의 시작 지점을 가리키는 포인터들의 목록입니다.
- ITable Method Entry: 실제 인터페이스에 정의된 메서드들의 구현체 주소가 담긴 슬롯입니다.
객체가 여러 개의 인터페이스를 구현할수록 이 테이블은 인터페이스 단위로 그룹화되어 확장됩니다. JVM은 런타임에 현재 호출된 인터페이스가 ITable의 어디서부터 시작되는지 먼저 찾아낸 뒤, 그 시작점으로부터 메서드 오프셋을 더해 실제 호출 주소를 결정합니다.
호출 오버헤드
인터페이스 메서드 호출이 일반 메서드 호출보다 미세하게 느린 이유는 이 ‘이중 탐색’ 때문입니다. VTable은 객체의 타입을 알면 즉시 특정 인덱스로 접근할 수 있는 반면, ITable은 구현된 인터페이스 목록을 순회하거나 해시 테이블을 통해 해당 인터페이스의 메서드 그룹을 먼저 찾아야 합니다.
현대의 JVM은 이를 최적화하기 위해 Inline Caching과 같은 기술을 사용하지만, 논리적 구조상 ITable은 VTable보다 한 단계 더 깊은 간접 참조(Indirection)를 수반합니다. 특히 수십 개의 인터페이스를 구현한 복잡한 클래스의 경우, ITable 탐색 비용은 무시할 수 없는 변수가 됩니다.
ITable의 파편화
클래스가 구현하는 인터페이스가 늘어날수록 ITable은 메모리상에서 파편화된 구조를 갖게 됩니다. 이는 CPU의 분기 예측(Branch Prediction)을 어렵게 만들고, 캐시 미스를 유발할 가능성을 높입니다. ‘인터페이스 중심 설계’가 아키텍처적으로는 우아할지 몰라도, 바이너리 수준에서는 시스템에 추가적인 탐색 비용을 청구하고 있는 셈입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
import org.openjdk.jol.info.ClassLayout;
/**
* VTable(invokevirtual)과 ITable(invokeinterface)의 구조적 차이 분석
*/
public class InterfaceDispatchAnalysis {
// 1. VTable 경로: 클래스 상속
static class BaseClass {
public void perform() { /* 상속을 통한 호출 */ }
}
static class VTableImpl extends BaseClass {
@Override public void perform() { }
}
// 2. ITable 경로: 인터페이스 구현
interface Action {
void perform();
}
static class ITableImpl implements Action {
@Override public void perform() { }
}
public static void main(String[] args) {
VTableImpl vTableObj = new VTableImpl();
ITableImpl iTableObj = new ITableImpl();
System.out.println("=== 1. 인스턴스 레이아웃 비교 (Heap 영역) ===");
// 두 객체 모두 동일한 헤더(Klass Word)를 가짐을 확인
System.out.println("VTable Class Layout:\n" + ClassLayout.parseInstance(vTableObj).toPrintable());
System.out.println("ITable Class Layout:\n" + ClassLayout.parseInstance(iTableObj).toPrintable());
System.out.println("=== 2. 호출 메커니즘 추론 (Metaspace 영역) ===");
// 시나리오 A: invokevirtual (VTable)
// Klass Word -> VTable -> [Fixed Index] -> Method Address
vTableObj.perform();
System.out.println("[VTable] 직접 인덱싱을 통한 빠른 점프 가능");
// 시나리오 B: invokeinterface (ITable)
// Klass Word -> ITable -> [Search Interface Offset] -> [Method Index] -> Method Address
Action action = iTableObj;
action.perform();
System.out.println("[ITable] 인터페이스 오프셋 탐색 단계가 추가로 필요");
}
}
🧩 Compressed OOPs
현대 하드웨어가 64비트로 전환되면서 우리는 이론적으로 16EB(엑사바이트)라는 무한에 가까운 메모리를 사용할 수 있게 되었습니다. 하지만 소프트웨어 엔지니어링에는 공짜 점심이 없습니다. 64비트 주소 체계는 포인터 하나를 저장하는 데 8바이트를 소모하며, 이는 32비트 환경 대비 두 배의 메모리 낭비와 CPU 캐시 효율 저하를 초래했습니다. JVM은 이 문제를 해결하기 위해 Compressed OOPs(Ordinary Object Pointers)라는 영리한 압축 기술을 도입했습니다.
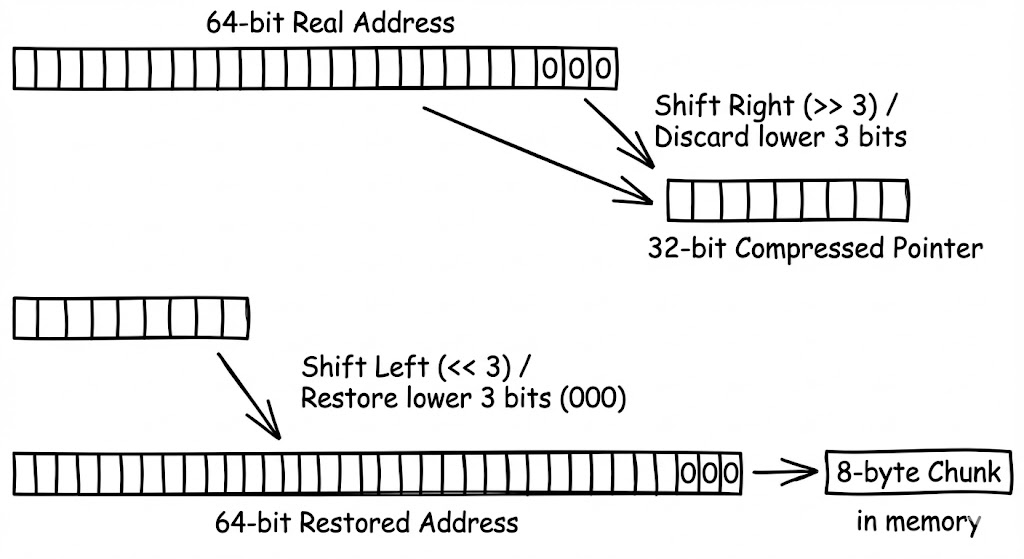
포인터 압축과 복원
32비트 포인터는 최대 4GB($2^{32}$)의 메모리만 가리킬 수 있습니다. 하지만 JVM은 모든 객체를 8바이트 경계에 정렬(Alignment)한다는 사실에 주목했습니다. 모든 객체의 시작 주소가 8의 배수라면, 주소값의 하위 3비트는 항상 0일 수밖에 없습니다.
JVM은 이 ‘항상 0인 3비트’를 제거하고 주소값을 저장합니다. 즉, 실제 물리 주소를 8로 나눈 값(3비트 우측 시프트)을 32비트 포인터에 담는 것입니다. 이렇게 하면 32비트 공간에 $2^{32} \times 8$ 바이트, 즉 32GB까지의 주소 공간을 표현할 수 있게 됩니다. CPU가 이 포인터를 사용할 때는 다시 좌측으로 3비트를 밀어(Left Shift) 원래의 64비트 주소를 복원합니다.
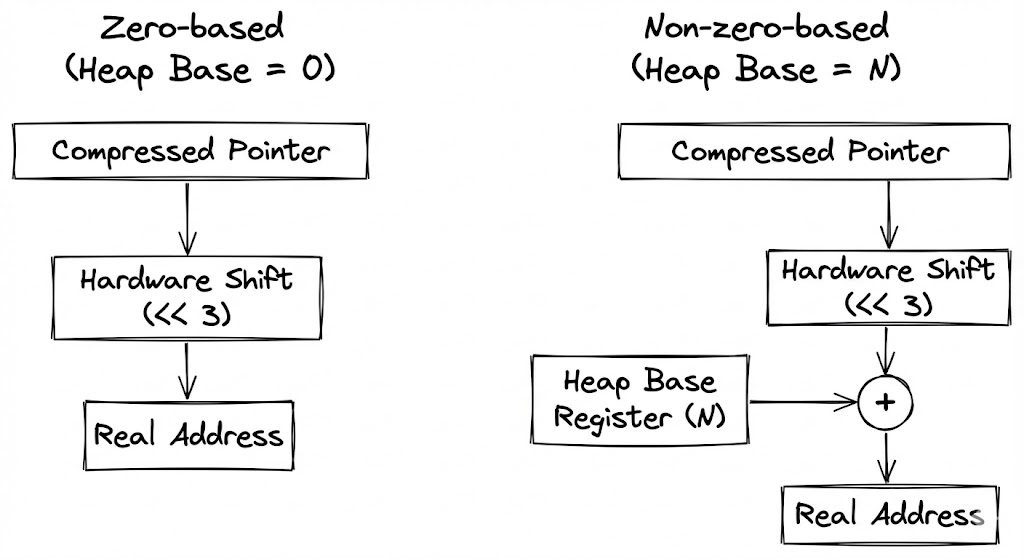
Zero-based Heap
비트 시프팅을 통한 주소 복원은 매우 빠르지만, 만약 힙 메모리가 시스템의 0번지부터 시작하지 않는다면 추가적인 연산이 필요합니다. 복원된 주소에 힙의 시작 주소(Base Address)를 더해야 하기 때문입니다.
JVM은 이를 최적화하기 위해 가능한 한 힙을 메모리의 낮은 주소 영역에 배치하여 시작 주소를 0으로 만드는 Zero-based Heap 전략을 사용합니다. 시작 주소가 0이라면 단순히 비트를 미는 것만으로 물리 주소를 얻을 수 있어 연산 비용이 거의 제로에 수렴합니다. 하지만 시스템 예약 영역 등으로 인해 0번지 배치가 불가능해지면, JVM은 베이스 주소를 더하는 오버헤드를 감수하거나 압축 자체를 포기하게 됩니다.
32GB의 장벽
많은 엔지니어가 힙 크기를 31GB나 32GB 직전으로 설정하는 이유가 바로 여기에 있습니다. 32GB를 단 1바이트라도 넘어서는 순간, JVM은 8바이트 정렬만으로는 모든 주소를 32비트에 담을 수 없다고 판단하고 압축 포인터 사용을 중단합니다. 이 경우 모든 포인터가 8바이트로 늘어나면서, 오히려 32GB일 때보다 가용 메모리가 수 GB 줄어드는 역설적인 상황이 발생합니다.
Case Studies
이론의 모호함을 걷어내기 위해, 실제 JVM 위에서 인스턴스가 조립되는 과정을 구체적인 시나리오를 통해 전수 조사합니다. 각 사례는 객체가 정의된 소스 코드 레벨부터 그것이 메모리 덤프 상에서 어떤 바이트 패턴으로 실체화되는지 그 동작 메커니즘을 추적합니다.
Case 1. 단일 클래스
상속 계층이 java.lang.Object에 그치며, 추가적인 인터페이스를 구현하지 않은 가장 원자적인 형태의 클래스 인스턴스입니다. 외부의 개입 없이 오직 자신의 필드만으로 메모리를 구성하는 ‘순수 객체’의 레이아웃을 정의합니다.
우리는 2차원 평면의 좌표를 나타내는 간단한 Vector2D 클래스를 가정합니다. 이 클래스는 두 개의 int 타입 필드 x와 y를 가집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 단일 클래스(Vector2D)의 기본 레이아웃과 헤더/필드/패딩의 조화
*/
public class Vector2DAnatomy {
// 2차원 좌표를 나타내는 원자적 클래스
static class Vector2D {
int x; // 4 bytes
int y; // 4 bytes
}
public static void main(String[] args) {
// 1. JVM 환경 확인 (Compressed OOPs 활성화 여부 등)
System.out.println(VM.current().details());
System.out.println("--------------------------------------------------\n");
// 2. Vector2D 인스턴스 생성
Vector2D vector = new Vector2D();
// 3. 물리적 메모리 레이아웃 출력
System.out.println("=== [Vector2D 인스턴스의 메모리 동작 메커니즘 분석] ===");
System.out.println(ClassLayout.parseInstance(vector).toPrintable());
}
}
64비트 HotSpot JVM(Compressed OOPs 활성화) 환경에서 new Vector2D()가 호출되면, 메모리에는 다음과 같은 순차적 조립이 일어납니다.
- 헤더 배치 (0~11 Byte): 8바이트의 Mark Word와 4바이트의 Klass Word가 가장 먼저 자리를 잡습니다. 이 12바이트는 객체의 신분증과 클래스 정보 포인터로 사용됩니다.
- 필드 할당 (12~19 Byte): 첫 번째 필드
int x가 12번 오프셋부터 4바이트를 차지합니다. 이어서 두 번째 필드int y가 16번 오프셋부터 4바이트를 차지하여 정확히 19번 바이트까지 데이터를 채웁니다. - 경계 정렬과 패딩 (20~23 Byte): 지금까지 채워진 크기는 총 20바이트입니다. 그러나 JVM은 메모리 읽기 효율을 위해 객체 크기를 항상 8의 배수로 맞춥니다. 따라서 마지막에 4바이트의 무의미한 데이터인 ‘정렬 패딩(Alignment Padding)’을 추가하여 최종 24바이트의 메모리 블록을 완성합니다.
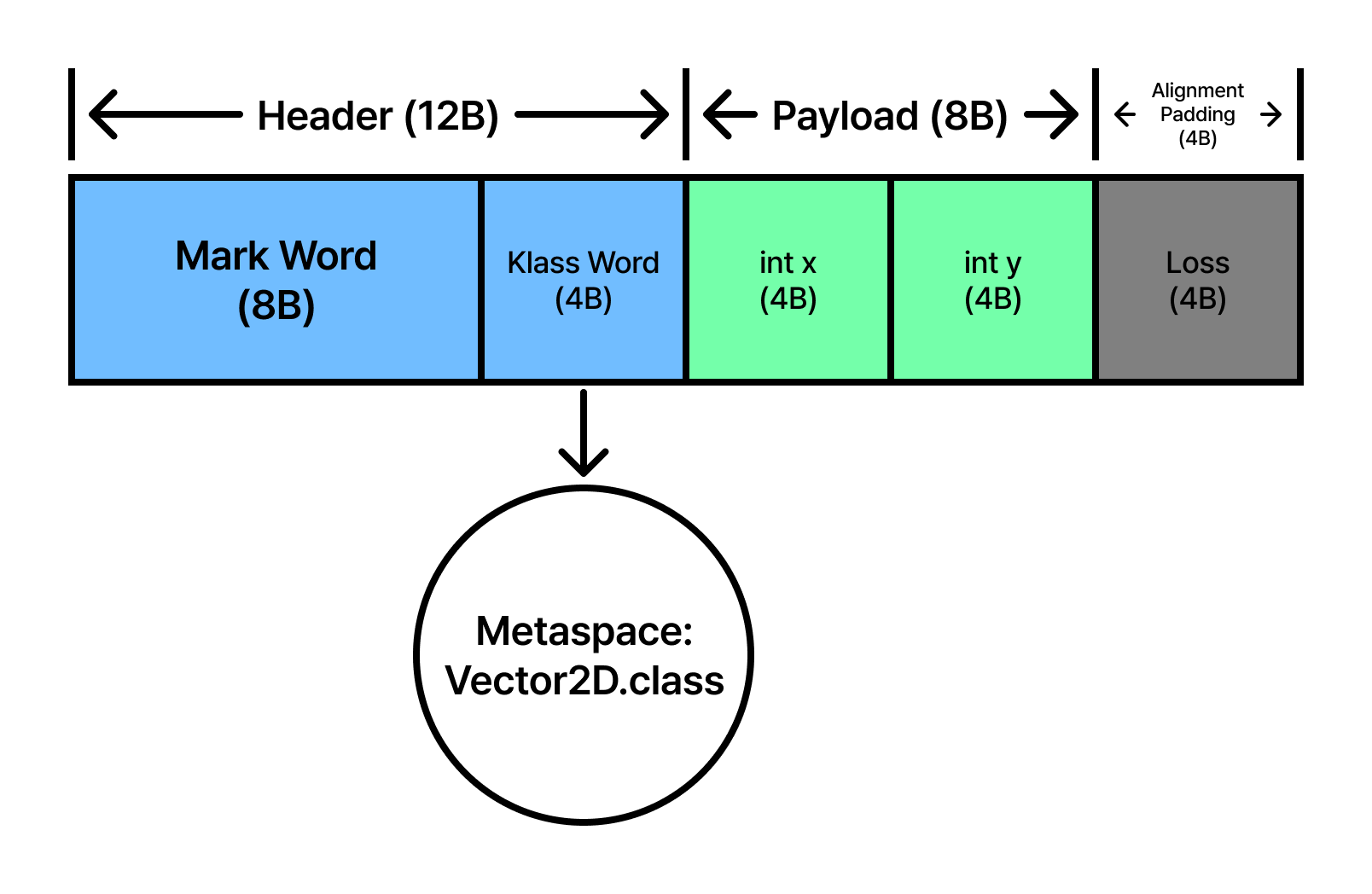
이 과정에서 핵심은 JVM이 필드 사이의 빈틈을 최소화하려 한다는 점입니다. 만약 x가 byte 타입이었다면, y와의 사이에 미세한 내부 패딩이 발생했을 것입니다. 하지만 위 예시에서는 필드 크기가 균일하여 외부 패딩만으로 깔끔하게 마감되었습니다.
4바이트의 경제학
Vector2D객체 하나는 데이터(8바이트)보다 메타데이터와 패딩(16바이트)의 무게가 두 배 더 큽니다. 만약 수백만 개의 좌표를 다루는 게임 엔진을 만든다면, 이를 객체 배열이 아닌 프리미티브 배열(int[] x,int[] y)로 관리하는 것이 왜 메모리 측면에서 압도적으로 유리한지 이 레이아웃이 증명해 줍니다.
Case 2. 단순 상속
부모 클래스(Base)를 자식 클래스(Derived)가 확장하는 전형적인 상속 시나리오입니다. 이 과정에서 JVM이 부모로부터 물려받은 필드와 자식이 새로 추가한 필드를 어떤 순서로 배치하며, 부모 타입으로의 형변환(Upcasting) 시에도 데이터 접근 속도를 어떻게 유지하는지 분석합니다.
모든 데이터의 기본이 되는 id를 가진 BaseEntity와, 이를 상속받아 age 정보를 추가한 User 클래스를 가정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 상속 구조에서의 필드 선형 확장과 오프셋 고정 원리 실측
*/
public class InheritanceLayoutAnatomy {
// 부모 클래스: 고유 ID를 가짐
static class BaseEntity {
int id; // 4 bytes
}
// 자식 클래스: 부모를 상속받고 나이 정보를 추가
static class User extends BaseEntity {
int age; // 4 bytes
}
public static void main(String[] args) {
// 1. JVM 환경 정보 출력
System.out.println(VM.current().details());
System.out.println("--------------------------------------------------\n");
// 2. User 인스턴스 생성
User user = new User();
// 3. 물리적 메모리 레이아웃 출력
System.out.println("=== [User 인스턴스(상속 구조)의 메모리 동작 메커니즘 분석] ===");
System.out.println(ClassLayout.parseInstance(user).toPrintable());
}
}
new User()가 호출되어 힙 영역에 메모리가 할당될 때, JVM은 ‘선형적 누적’ 원칙에 따라 레이아웃을 설계합니다.
- 객체 헤더 (0~11 Byte): 인스턴스의 타입은
User이지만, 헤더는 항상 최상단에 위치합니다. Klass Word는User클래스의 메타데이터를 가리킵니다. - 부모 필드 우선 배치 (12~15 Byte): 자식의 필드보다 부모인
BaseEntity의int id가 먼저 배치됩니다. 이는 매우 중요한 설계적 결정입니다.User인스턴스를BaseEntity타입으로 바라보더라도id필드의 오프셋(12번)이 변하지 않아야 하기 때문입니다. - 자식 필드 확장 (16~19 Byte): 부모의 데이터 영역이 끝나는 지점 바로 뒤에
User클래스의 고유 필드인int age가 붙습니다. - 전체 정렬 패딩 (20~23 Byte): 총 20바이트의 데이터를 8바이트 경계에 맞추기 위해 마지막에 4바이트 패딩이 추가되어 총 24바이트가 됩니다.
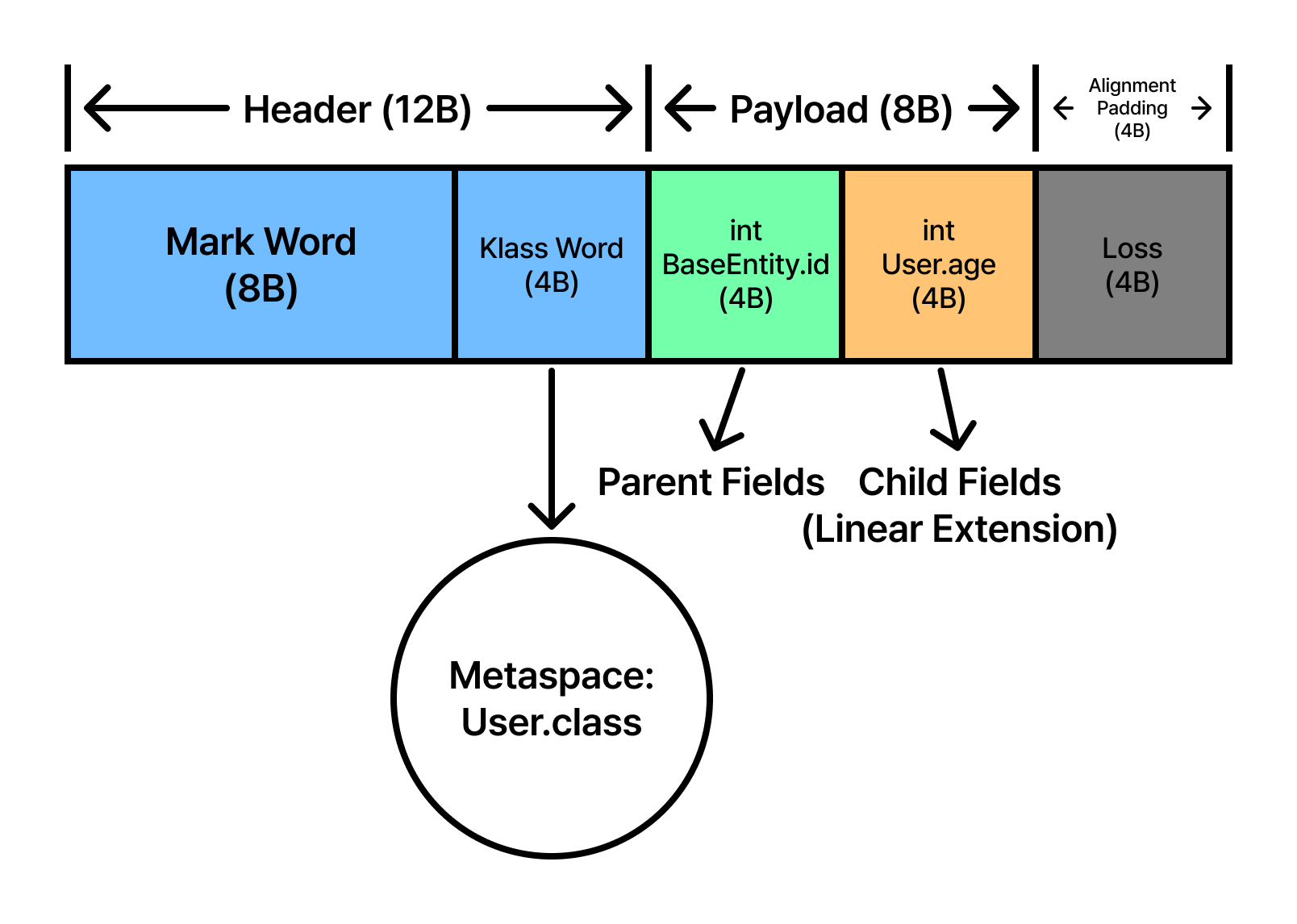
이 메커니즘을 통해 JVM은 다형성을 지원합니다. 실행 엔진은 객체가 BaseEntity인지 User인지 상관없이 “객체 시작점으로부터 12바이트 떨어진 곳에 id가 있다”는 사실을 신뢰할 수 있습니다. 상속은 메모리 관점에서 보면 단순히 부모의 설계도 뒤에 자식의 설계도를 ‘이어 붙이는’ 작업인 셈입니다.
Padding Gap
부모 클래스의 마지막 필드가 4바이트(
int)로 끝나고 자식 클래스의 첫 필드가 8바이트(long)인 경우, 8바이트 정렬을 맞추기 위해 부모와 자식 영역 사이에 4바이트의 빈 공간(Gap)이 생길 수 있습니다. JVM은 이 틈새를 효율적으로 활용하기 위해 자식의 작은 필드들을 위로 끌어올리는 최적화를 시도하기도 합니다.
Case 3. 다단계 상속
조부모 클래스부터 부모를 거쳐 손자 클래스까지 이어지는 깊은 상속 계층에서의 메모리 레이아웃을 분석합니다. 여러 단계의 상속이 발생할 때 JVM이 각 계층의 데이터를 어떻게 순차적으로 적층(Stacking)하며, 이 과정에서 발생하는 누적된 패딩(Padding)이 전체 인스턴스 크기에 어떤 영향을 미치는지 확인합니다.
전자 기기의 정보를 담는 Device 클래스, 이를 상속받은 Computer, 그리고 최종적으로 Laptop 클래스로 이어지는 3단계 구조를 가정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 다단계 상속에서의 필드 적층(Stacking)과 누적 패딩 실측
*/
public class MultiLevelInheritanceAnatomy {
// 조부모 클래스 (GrandParent)
static class Device {
long serial; // 8 bytes
}
// 부모 클래스 (Parent)
static class Computer extends Device {
int cpu; // 4 bytes
}
// 손자 클래스 (Child)
static class Laptop extends Computer {
short weight; // 2 bytes
}
public static void main(String[] args) {
// 1. JVM 환경 정보 출력
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
// 2. Laptop 인스턴스 생성
Laptop laptop = new Laptop();
// 3. 물리적 메모리 레이아웃 출력
System.out.println("=== [Laptop 인스턴스(3단계 상속)의 메모리 동작 메커니즘 분석] ===");
System.out.println(ClassLayout.parseInstance(laptop).toPrintable());
}
}
new Laptop()이 호출되면 JVM은 최상위 조상부터 최하위 자식까지의 모든 필드를 하나의 데이터 풀로 간주하고, 메모리 낭비를 최소화하기 위해 필드 배치를 재구성합니다.
- 최상위 헤더 (0~11 Byte): 객체의 정체성을 정의하는 12바이트 헤더가 위치하며, 64비트 환경에서 헤더가 12번지에서 종료됨에 따라 12~15번지에 4바이트 크기의 ‘헤더 빈틈(Header Gap)’이 발생합니다.
- 틈새 공략 및 재배치 (12~15 Byte): 원래 조부모의
long serial이 올 차례지만, 8바이트 정렬 규칙상 12번지에 들어갈 수 없습니다. JVM은 이 4바이트 틈을 메우기 위해 상속 계층을 뒤져 부모 클래스의int Computer.cpu를 최상단으로 전진 배치하는 최적화를 수행합니다. - GrandParent 영역 (16~23 Byte): 4바이트 빈틈이 메워진 덕분에 다음 가용한 오프셋이 8의 배수인 16번지로 조정됩니다. 이제 조부모 클래스의
long Device.serial이 물리적 정렬 규칙에 맞춰 안정적으로 안착합니다. - Child 영역 (24~25 Byte): 부모들의 데이터 배치가 끝난 지점 바로 뒤에 손자 클래스의 고유 필드인
short Laptop.weight가 2바이트를 차지하며 선형적으로 확장됩니다. - 최종 패딩 (26~31 Byte): 현재까지 사용된 데이터는 총 26바이트입니다. 8바이트 경계 정렬을 완결하기 위해 JVM은 마지막에 6바이트의 거대한 패딩을 추가하여 최종 32바이트의 메모리 블록을 완성합니다.
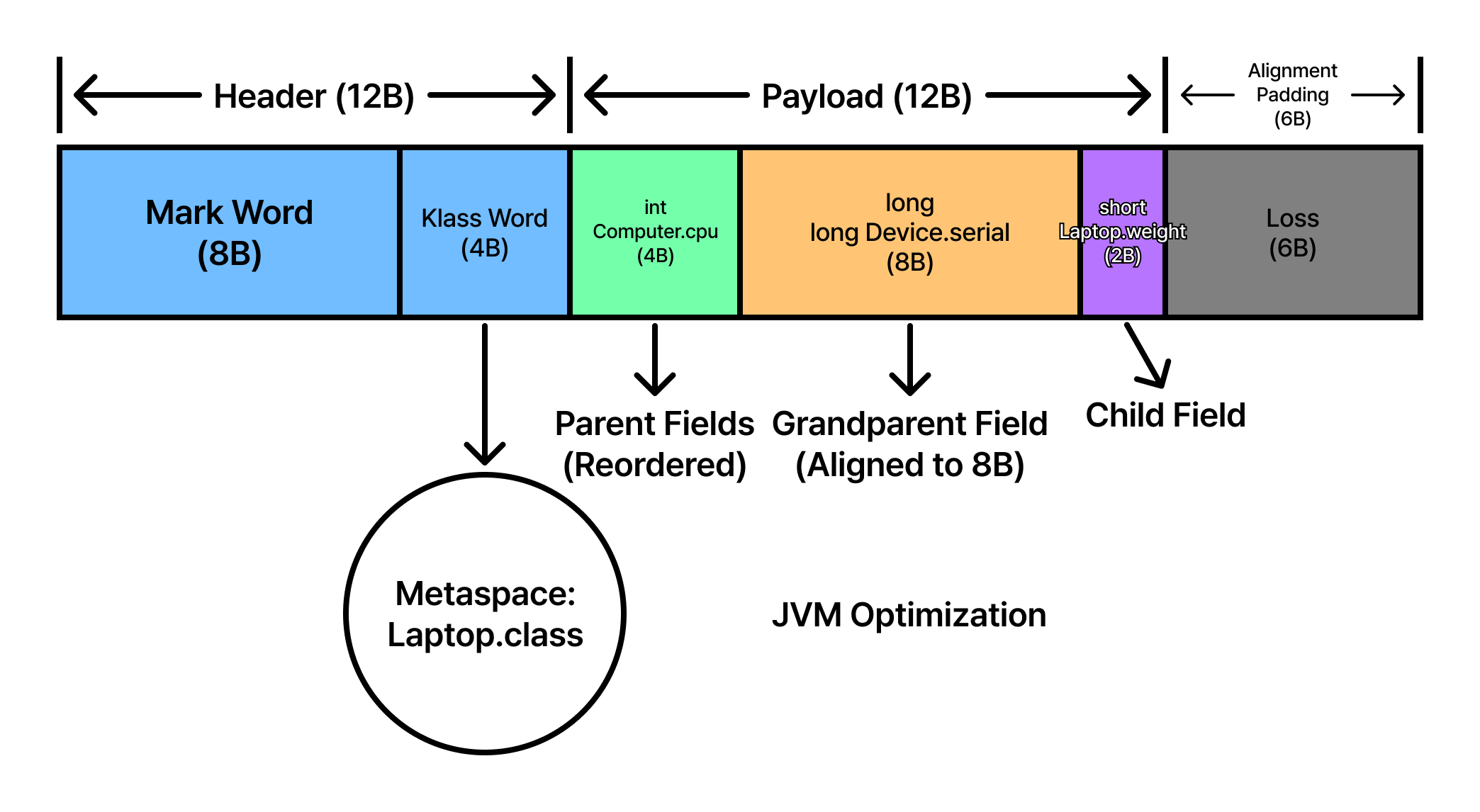
깊은 상속의 비용
상속은 ‘Is-A’ 관계를 표현하는 강력한 도구이지만, 메모리 관점에서는 조상들이 남긴 모든 데이터 부채를 자식이 짊어지는 과정입니다. 상속 계층이 너무 깊어지면 객체 하나를 생성할 때마다 불필요한 메타데이터와 패딩이 누적되므로, 데이터 집약적인 시스템에서는 상속보다는 ‘조합(Composition)’을 권장하는 물리적인 이유가 여기에 있습니다.
Case 4. 필드 쉐도잉
부모 클래스에 정의된 필드와 동일한 이름을 가진 필드를 자식 클래스에서 다시 선언하는 경우입니다. 자바에서 메서드는 오버라이딩(Overriding)을 통해 부모의 구현을 완전히 대체하지만, 필드는 ‘쉐도잉(Shadowing)’이라 불리는 전혀 다른 메커니즘을 따릅니다. 이 사례를 통해 물리적 메모리 계층에서 이름이 같은 두 데이터가 어떻게 공존하며, 참조 타입에 따라 접근 지점이 어떻게 달라지는지 해부합니다.
기본 보너스 점수를 가진 Account 클래스와, 이를 상속받아 더 높은 보너스 점수를 동일한 필드명(bonus)으로 재정의한 VIPAccount 클래스를 가정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
/**
* 필드 쉐도잉(Field Shadowing)에 의한 물리적 메모리 공존 및 정적 바인딩 실측
*/
public class FieldShadowingAnatomy {
static class Account {
int bonus = 100; // 부모의 보너스
}
static class VIPAccount extends Account {
int bonus = 500; // 자식의 보너스 (Shadowing)
}
public static void main(String[] args) {
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
VIPAccount vip = new VIPAccount();
Account accountRef = vip; // 업캐스팅
// 1. 참조 타입별 필드 접근 결과 (정적 바인딩 확인)
System.out.println("=== [참조 타입에 따른 필드 접근 결과] ===");
System.out.println("VIPAccount ref bonus: " + vip.bonus); // 자식 필드 접근
System.out.println("Account ref bonus: " + accountRef.bonus); // 부모 필드 접근
System.out.println();
// 2. 물리적 메모리 레이아웃 출력
System.out.println("=== [VIPAccount 인스턴스의 메모리 맵 (Field Shadowing)] ===");
System.out.println(ClassLayout.parseInstance(vip).toPrintable());
}
}
new VIPAccount()가 실행되면 JVM은 “이름이 같으니 하나를 덮어쓰자”고 판단하지 않습니다. 대신 부모의 데이터 영역과 자식의 데이터 영역에 각각의 공간을 독립적으로 할당합니다.
- 부모 영역 필드 (12~15 Byte):
Account클래스에서 정의한int bonus필드가 부모 영역 오프셋에 먼저 배치됩니다. - 자식 영역 필드 (16~19 Byte):
VIPAccount클래스에서 새로 선언한int bonus필드가 자식 영역 오프셋에 별도로 배치됩니다. - 메모리 맵의 공존: 결과적으로 하나의 인스턴스 내부에 이름이 ‘bonus’인 공간이 두 개 존재하게 됩니다. 하나는 부모의 것이고, 다른 하나는 자식의 것입니다.
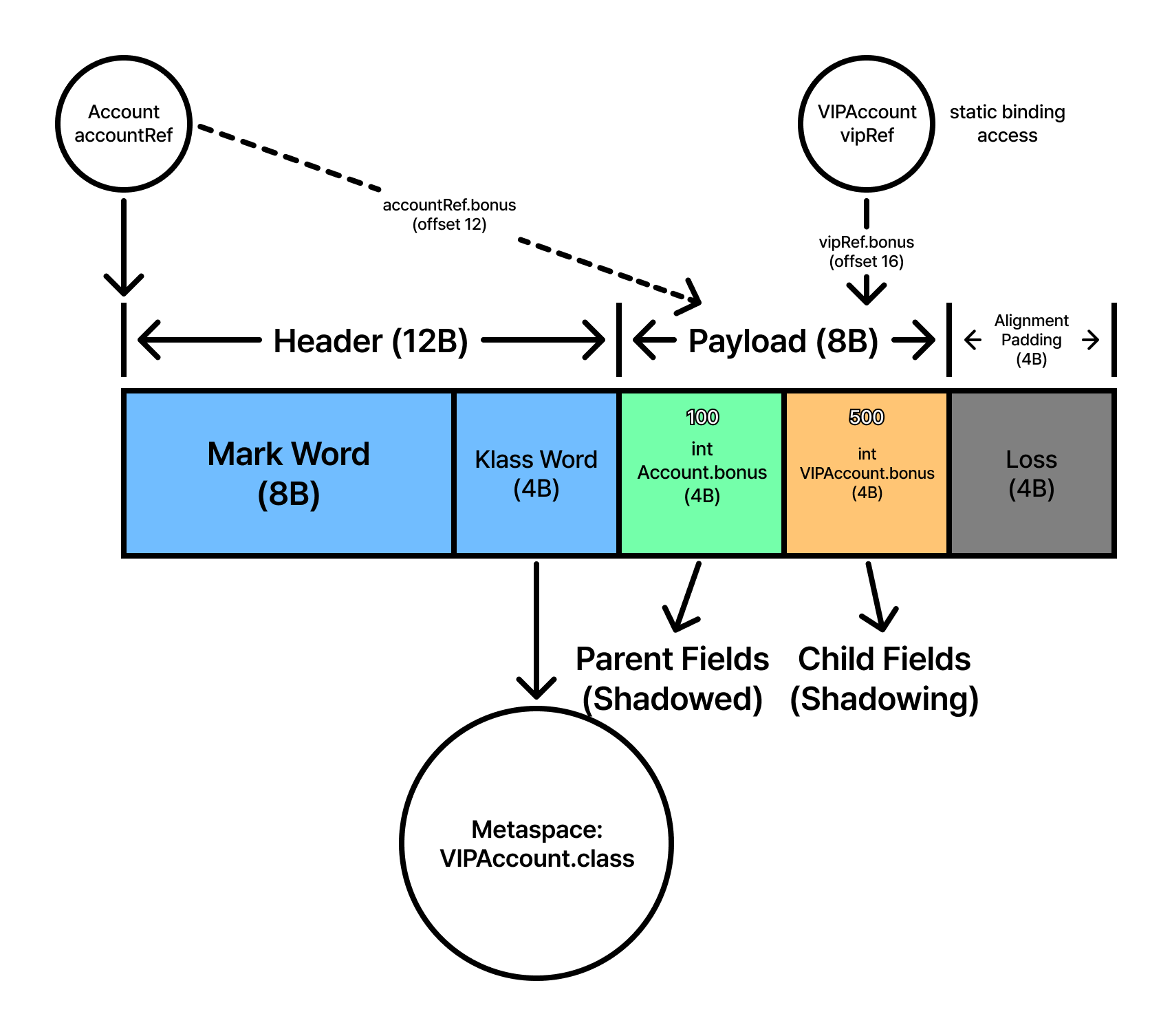
이러한 물리적 배치는 자바의 필드 접근이 정적 바인딩(Static Binding)을 따르기 때문에 발생합니다. 컴파일러는 소스 코드에서 account.bonus를 발견하면, 실행 시점의 실제 객체가 무엇인지 묻지 않고 account 변수의 ‘타입’을 기준으로 이미 결정된 메모리 오프셋 주소를 코드에 박아 넣습니다.
부모 타입으로 접근하면 12번 오프셋을 읽고, 자식 타입으로 접근하면 16번 오프셋을 읽는 식입니다. 이는 VTable을 통해 실행 주소를 찾아가는 메서드 호출(Dynamic Dispatch)과는 완전히 대조적인 동작입니다. 데이터의 무결성을 지키기 위해 JVM은 이름을 버리고 오로지 ‘오프셋 주소’로만 소통하는 셈입니다.
필드 쉐도잉의 위험성
필드 쉐도잉은 코드의 가독성을 심각하게 해칠 뿐만 아니라, 메모리 덤프 분석 시 혼란을 야기합니다. 동일한 인스턴스 내에 같은 이름의 변수가 두 개 존재한다는 것은 메모리 낭비일 뿐만 아니라 의도치 않은 버그의 온상이 됩니다. 만약 부모의 필드 값을 변경해야 할 상황에서 자식의 쉐도잉된 필드만 수정한다면, 부모 타입으로 캐스팅되어 동작하는 로직은 여전히 옛날 데이터를 바라보게 될 것입니다.
Case 5. 단일 인터페이스 구현
클래스 상속과는 별개로, 특정 인터페이스를 하나 구현했을 때의 메모리 변화를 추적합니다. 인터페이스는 클래스 계층 구조에 종속되지 않으므로 VTable의 고정 인덱스를 사용할 수 없습니다. 이 시나리오에서는 JVM이 인터페이스 메서드 호출을 위해 도입한 ITable(Interface Method Table)이 클래스 메타데이터 내에 어떻게 생성되며, 인스턴스 레이아웃과는 어떤 참조 관계를 맺는지 분석합니다.
비행 기능을 정의한 Flyable 인터페이스와, 이를 구현하여 실제 비행 로직을 가진 Drone 클래스를 가정합니다. Drone은 내부에 battery 상태를 가집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 인터페이스 구현에 따른 인스턴스 레이아웃 유지 및 ITable 간접 참조 분석
*/
public class InterfaceImplementationAnatomy {
// 인터페이스 정의 (능력 부여)
interface Flyable {
void fly();
}
// 인터페이스 구현 클래스 (상태 + 구현)
static class Drone implements Flyable {
int battery = 100;
@Override
public void fly() {
System.out.println("Drone is flying... Battery: " + battery + "%");
}
}
public static void main(String[] args) {
// 1. JVM 환경 정보
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
// 2. 인터페이스 타입으로 인스턴스 참조
Flyable drone = new Drone();
// 3. 인스턴스 레이아웃 출력 (Heap 영역 확인)
System.out.println("=== [Drone 인스턴스의 메모리 맵 (Heap)] ===");
System.out.println(ClassLayout.parseInstance(drone).toPrintable());
// 4. 인터페이스 메서드 호출 (invokeinterface 동작 시뮬레이션)
System.out.print("drone.fly() 호출 결과: ");
drone.fly();
// 5. Klass Word가 가리키는 Metaspace 물리 주소 추출
// JOL 출력에서 본 VALUE는 '압축된 별명'입니다.
// 아래 코드는 JVM이 그 별명을 해독(Decoding)하여 찾아낸 '진짜 64비트 절대 주소'를 가져옵니다.
long klassPointer = VM.current().addressOf(drone.getClass());
System.out.println("\n=== [ITable 탐색의 시작점: 물리 주소 및 영역 해독] ===");
System.out.printf("1. Drone 인스턴스 주소 (Heap 영역) : 0x%x%n", VM.current().addressOf(drone));
System.out.printf("2. Drone 클래스 메타데이터 주소 (Metaspace) : 0x%x%n", klassPointer);
}
}
Flyable drone = new Drone(); 코드가 실행될 때, 메모리의 물리적 배치는 다음과 같은 정교한 이중 구조를 형성합니다.
- 인스턴스 레이아웃 (Heap): 힙에 생성된
Drone인스턴스 자체는 인터페이스 구현 여부와 상관없이 이전 사례들과 동일한 구조를 유지합니다. 헤더(12B) +int battery(4B)로 구성된 16바이트 블록입니다. 인터페이스를 구현했다고 해서 객체 내부에 특별한 데이터가 추가되지는 않습니다. - 메타데이터 내 ITable 생성 (Metaspace): 진짜 변화는
Drone클래스의 설계도인InstanceKlass내부에서 일어납니다. JVM은 클래스를 로딩할 때Flyable인터페이스를 위한 전용 ITable 영역을 확보합니다. - 참조의 흐름:
drone.fly()를 호출하면 실행 엔진은 다음 단계를 거칩니다.- 객체 헤더의 Klass Word를 통해
Drone클래스의 메타데이터로 이동합니다. - VTable 영역을 지나 그 뒤에 위치한 ITable 영역에서
Flyable인터페이스에 해당하는 엔트리를 찾습니다. - 해당 엔트리가 가리키는 메서드 테이블에서
fly()의 실제 구현 주소를 찾아 점프합니다.
- 객체 헤더의 Klass Word를 통해
이 메커니즘에서 중요한 점은 ‘간접 참조의 추가’입니다. VTable은 오프셋이 고정되어 있어 즉시 접근이 가능하지만, 인터페이스는 해당 클래스가 어떤 인터페이스들을 구현했는지 목록을 훑어야 하므로 한 단계의 탐색 비용이 더 발생합니다. JVM은 단일 인터페이스 구현의 경우 이를 VTable처럼 최적화하려 노력하지만, 구조적으로는 여전히 ITable이라는 별도의 주소록을 참조하게 됩니다.
구현과 타입의 분리
메모리 수준에서 보면 인터페이스 구현은 객체의 ‘상태(필드)’를 건드리지 않고 ‘능력(메서드 주소록)’만 확장하는 작업입니다. 이는 데이터 레이아웃의 변형 없이도 객체에 새로운 페르소나를 부여할 수 있게 하며, 자바 다형성이 클래스라는 단단한 틀을 넘어 유연하게 확장될 수 있는 물리적 토대가 됩니다.
Case 6. 다중 인터페이스 구현
하나의 클래스가 두 개 이상의 인터페이스를 동시에 구현할 때 발생하는 메모리 레이아웃의 변화를 다룹니다. 자바는 클래스 다중 상속은 금지하지만 인터페이스 다중 구현은 허용합니다. 이 유연성을 뒷받침하기 위해 JVM이 ITable(Interface Method Table)을 어떻게 확장하며, 서로 다른 인터페이스에서 오는 메서드들을 물리적으로 어떻게 격리하여 관리하는지 분석합니다.
전화 기능을 정의한 Phone 인터페이스와 사진 촬영 기능을 정의한 Camera 인터페이스를 동시에 구현하는 SmartPhone 클래스를 가정합니다. SmartPhone은 내부적으로 modelName 필드를 가집니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
import java.io.IOException;
/**
* 다중 인터페이스 구현 시의 ITable 확장 및 영역 격리 메커니즘 실측
*/
public class MultiInterfaceAnatomy {
interface Phone { void call(); }
interface Camera { void takePhoto(); }
// 두 인터페이스를 동시 구현
static class SmartPhone implements Phone, Camera {
String modelName = "Galaxy S26"; // Reference (4B with Compressed OOPs)
@Override public void call() { System.out.println("Calling..."); }
@Override public void takePhoto() { System.out.println("Taking photo..."); }
}
public static void main(String[] args) {
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
SmartPhone myPhone = new SmartPhone();
// 1. 인스턴스 레이아웃 출력 (Heap 영역)
System.out.println("=== [SmartPhone 인스턴스의 메모리 맵 (Heap)] ===");
System.out.println(ClassLayout.parseInstance(myPhone).toPrintable());
// 2. 다중 인터페이스 설계도(Klass) 주소 추출
long klassPointer = VM.current().addressOf(myPhone.getClass());
System.out.println("=== [ITable 다중 엔트리의 시작점: 메타데이터 주소] ===");
System.out.printf("Instance Address : 0x%x%n", VM.current().addressOf(myPhone));
System.out.printf("Klass Address : 0x%x (이곳에 Phone/Camera ITable이 위치)%n", klassPointer);
// 3. 다형적 호출 실행
Phone p = myPhone;
Camera c = myPhone;
p.call();
c.takePhoto();
System.out.println("\n[대기 중] 엔터를 누르면 종료됩니다. 이 상태에서 jhsdb를 실행하세요.");
try {
System.in.read(); // 프로세스 유지용
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
[Output]
# WARNING: Unable to get Instrumentation. Dynamic Attach failed. You may add this JAR as -javaagent manually, or supply -Djdk.attach.allowAttachSelf
# VM mode: 64 bits
# Compressed references (oops): 3-bit shift
# Compressed class pointers: 0-bit shift and 0x29A2E000000 base
# Object alignment: 8 bytes
# ref, bool, byte, char, shrt, int, flt, lng, dbl
# Field sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8
# Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8
# Array base offsets: 16, 16, 16, 16, 16, 16, 16, 16, 16
----------------------------------
=== [SmartPhone 인스턴스의 메모리 맵 (Heap)] ===
posts.jvm_memory_layout.MultiInterfaceAnatomy$SmartPhone object internals:
OFF SZ TYPE DESCRIPTION VALUE
0 8 (object header: mark) 0x0000000000000001 (non-biasable; age: 0)
8 4 (object header: class) 0x0101f178
12 4 java.lang.String SmartPhone.modelName (object)
Instance size: 16 bytes
Space losses: 0 bytes internal + 0 bytes external = 0 bytes total
=== [ITable 다중 엔트리의 시작점: 메타데이터 주소] ===
Instance Address : 0x621b1e720
Klass Address : 0x621b1e5e0 (이곳에 Phone/Camera ITable이 위치)
Calling...
Taking photo...
SmartPhone 인스턴스가 생성되면, 힙 영역의 데이터 구조는 단순하지만 이를 뒷받침하는 메타스페이스(Metaspace)의 주소록은 비약적으로 복잡해집니다.
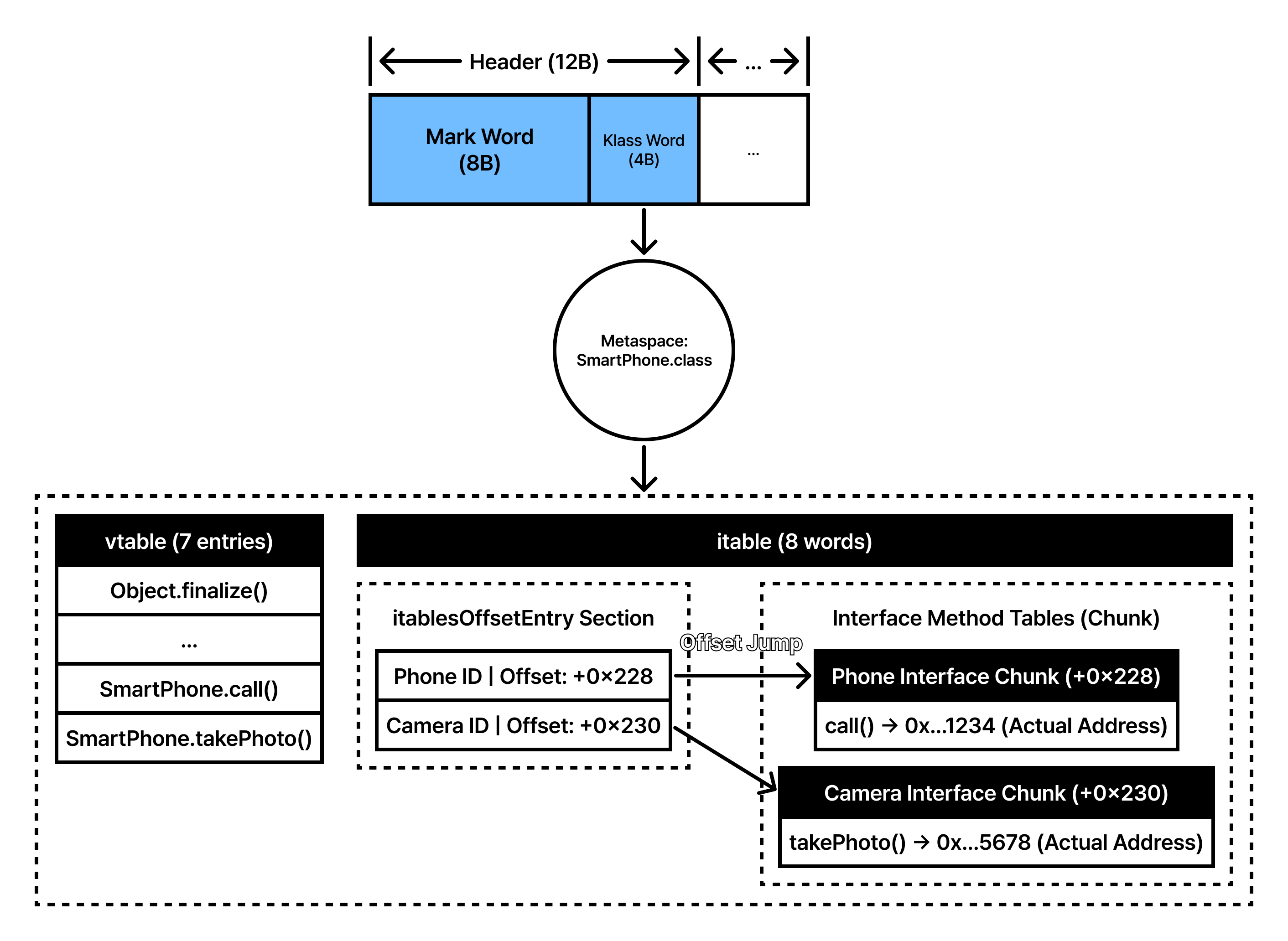
- ITable의 엔트리 확장: 단일 구현일 때는 하나의 인터페이스 블록만 존재했지만, 이제 ITable은 구현된 인터페이스 개수만큼의 ‘Offset Entry’를 가집니다.
Phone을 위한 시작 주소와Camera를 위한 시작 주소가 각각 기록됩니다. - 인터페이스별 메서드 그룹핑:
Phone인터페이스의call()메서드 주소와Camera인터페이스의takePhoto()메서드 주소는 ITable 내에서 서로 다른 영역(Chunk)에 배치됩니다. - 런타임 메서드 탐색(Search):
Phone p = new SmartPhone(); p.call();호출 시, JVM은 ITable에서Phone인터페이스 ID에 해당하는 오프셋을 먼저 찾습니다.- 찾아낸 오프셋 지점부터
call()메서드의 상대적 위치를 계산하여 실제 실행 주소를 얻습니다. - 인터페이스가 늘어날수록 이 ‘오프셋 탐색’ 과정에서 순회(Traversing)해야 할 엔트리가 많아져 미세한 오버헤드가 누적됩니다.
특히 흥미로운 점은 메서드 시그니처 충돌 처리입니다. 만약 두 인터페이스에 동일한 이름과 파라미터를 가진 메서드가 있다면, SmartPhone 클래스는 이를 하나로 구현하지만, ITable은 각 인터페이스의 관점에서 해당 구현체를 가리키는 포인터를 각각 유지합니다. 즉, 물리적으로는 같은 주소를 가리키더라도 주소록상의 엔트리는 인터페이스별로 독립적으로 관리되어 타입 안전성을 보장합니다.
ITable의 실체 확인
ITable이 위치한 Klass의 주소를 확인해보았습니다. 지금부터는 “ITable의 몇 번째 칸에 어떤 메서드가 들어있는가?”를 해결하여 ITable의 실체를 확인해보겠습니다.
1. clhsdb 실행 및 프로세스 연결
우선 자바 프로세스가 중단되지 않도록 System.in.read() 처리합니다. 그리고 터미널에서 JDK의 jhsdb 도구를 호출하여 clhsdb 모드로 진입한 뒤, 실행 중인 프로세스에 연결합니다.
1
2
3
4
5
# clhsdb 실행
jhsdb clhsdb
# 프로세스 연결
hsdb> attach <PID>
2. 클래스 주소(Klass) 찾기
ITable을 확인하기 위해서는 Klass의 실제 주소를 알아야 합니다. 코드의 출력에서 Base 주소(0x29A2E000000)와 4바이트로 압축된 Klass의 상대 주소(0x0101F178)를 통해 주소를 알고 있지만, clhsdb 자체 명령어로도 찾을 수 있습니다.
1
2
3
hsdb> class posts/jvm_memory_layout/MultiInterfaceAnatomy$SmartPhone
# posts/jvm_memory_layout/MultiInterfaceAnatomy$SmartPhone @0x0000029a2f01f178
3. VTable/ITable 크기 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
# inspect <확인한 Klass 주소>
hsdb> inspect 0x0000029a2f01f178
# Type is InstanceKlass (size of 448)
# ...
# int Klass::_vtable_len: 7
# ...
# Array<InstanceKlass*>* InstanceKlass::_local_interfaces: Array<InstanceKlass*> @ 0x0000029a6f46c6d8
# ...
# int InstanceKlass::_itable_len: 8
# ...
# int InstanceKlass::_nonstatic_field_size: 1
# ...
_vtable_len: 7(가상 메서드 테이블 길이):SmartPhone의 VTable에 7개의 엔트리가 기록되어 있음을 의미합니다.Object클래스로부터 상속받은 기본 메서드들(예:equals,hashCode,toString등)과SmartPhone클래스에서 직접 구현한 메서드들이 이 테이블에 순서대로 배치됩니다. 상속 계층을 따라 고정된 오프셋을 가지므로 호출 속도가 매우 빠릅니다._itable_len: 8(인터페이스 메서드 테이블 길이): 이번 실습의 핵심 지표입니다. 단일 인터페이스일 때보다 숫자가 커진 것을 확인할 수 있습니다. ITable은 단순히 메서드 주소만 적는 게 아니라, [인터페이스 클래스 주소 + 해당 메서드 그룹의 시작 오프셋] 정보를 포함하는itablesOffsetEntry와 실제 메서드 주소들이 결합된 구조이기 때문입니다.Phone과Camera두 개의 인터페이스를 구현했으므로, 각 인터페이스를 위한 엔트리와 메서드 포인터들이 누적되어 총 8워드(64바이트)의 공간을 점유하고 있는 것입니다._local_interfaces: Array<InstanceKlass*> @ 0x0000029a6f46c6d8: 이 주소는SmartPhone이 직접 구현한 인터페이스들의 리스트(Phone,Camera)를 담고 있는 배열을 가리킵니다. JVM은 인터페이스 메서드를 호출할 때 이 리스트를 참조하여 ITable 내에서 올바른 메서드 위치를 탐색합니다._nonstatic_field_size: 1: 객체 인스턴스 내부에 존재하는 필드의 개수입니다. 우리가 선언한String modelName필드 하나가 정상적으로 잡혀 있음을 보여줍니다.
4. 메모리 덤프로 VTable/ITable 실체 확인
mem 명령어를 사용하면 특정 주소부터 원하는 개수만큼의 메모리 데이터를 16진수로 출력합니다. InstanceKlass 구조체 바로 뒤에 VTable이 이어집니다.
1
2
# mem <확인한 Klass 주소>/<덤프할 워드 수>
hsdb> mem <확인한 Klass 주소>/100
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
[Output]
0x0000029a2f01f178: 0x00007ffa99373c10
0x0000029a2f01f180: 0x0000000000000010
0x0000029a2f01f188: 0x0000003800000008
0x0000029a2f01f190: 0x0000029a731d5898
0x0000029a2f01f198: 0x0000029a2f0033e8
0x0000029a2f01f1a0: 0x0000029a6f46c6d8
0x0000029a2f01f1a8: 0x0000029a2e000e70
0x0000029a2f01f1b0: 0x0000029a2f01f178
...
0x0000029a2f01f338: 0x0000029a2e001068
0x0000029a2f01f340: 0x0000029a2e0010c0
0x0000029a2f01f348: 0x0000029a2e001118
0x0000029a2f01f350: 0x0000029a2e001170
0x0000029a2f01f358: 0x0000029a2e0011d8
0x0000029a2f01f360: 0x0000029a6f46c818
0x0000029a2f01f368: 0x0000029a6f46c8c8
0x0000029a2f01f370: 0x0000029a2f0031f8
0x0000029a2f01f378: 0x0000000000000228
0x0000029a2f01f380: 0x0000029a2f0033e8
0x0000029a2f01f388: 0x0000000000000230
0x0000029a2f01f390: 0x0000000000000000
0x0000029a2f01f398: 0x0000000000000000
0x0000029a2f01f3a0: 0x0000029a6f46c818
0x0000029a2f01f3a8: 0x0000029a6f46c8c8
...
왼쪽 값(메모리 주소)은 데이터가 물리적으로 저장되어 있는 메타스페이스 내의 64비트 절대 주소이고, 오른쪽 값(데이터 값)은 해당 메모리 주소에 실제로 기록되어 있는 64비트 데이터입니다.
이전 inspect 결과에서 이 클래스의 InstanceKlass 크기가 448(0x1c0)임을 확인했습니다. 즉, VTable의 시작점은 InstanceKlass의 시작 주소인 0x0000029a2f01f178에서 크기 0x1c0만큼 떨어진 0x0000029a2f01f338입니다. 정확히 이 지점부터 의미있는 데이터들이 나타납니다.
덤프된 메모리 값들(0x…) 중 하나가 실제 메서드 주소인지 확인하기 위해 whatis 명령어를 사용합니다. 이 때, 메서드 객체의 실제 포인터를 가리키는 데이터 값을 입력해야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# whatis <덤프에서 발견한 메서드 추정 주소(데이터 값)>
hsdb> whatis 0x0000029a2e001068
# Address 0x0000029a2e001068: Method java/lang/Object.finalize()V@0x0000029a2e001068
hsdb> whatis 0x0000029a2e0010c0
# Address 0x0000029a2e0010c0: Method java/lang/Object.equals(Ljava/lang/Object;)Z@0x0000029a2e0010c0
hsdb> whatis 0x0000029a2e001118
# Address 0x0000029a2e001118: Method java/lang/Object.toString()Ljava/lang/String;@0x0000029a2e001118
hsdb> whatis 0x0000029a2e001170
# Address 0x0000029a2e001170: Method java/lang/Object.hashCode()I@0x0000029a2e001170
hsdb> whatis 0x0000029a2e0011d8
# Address 0x0000029a2e0011d8: Method java/lang/Object.clone()Ljava/lang/Object;@0x0000029a2e0011d8
hsdb> whatis 0x0000029a6f46c818
# Address 0x0000029a6f46c818: Method posts/jvm_memory_layout/MultiInterfaceAnatomy$SmartPhone.call()V@0x0000029a6f46c818
hsdb> whatis 0x0000029a6f46c8c8
# Address 0x0000029a6f46c8c8: Method posts/jvm_memory_layout/MultiInterfaceAnatomy$SmartPhone.takePhoto()V@0x0000029a6f46c8c8
hsdb> whatis 0x0000029a2f0031f8
# Address 0x0000029a2f0031f8: InstanceKlass for posts/jvm_memory_layout/MultiInterfaceAnatomy$Phone
hsdb> whatis 0x0000029a2f0033e8
# Address 0x0000029a2f0033e8: InstanceKlass for posts/jvm_memory_layout/MultiInterfaceAnatomy$Camera
이제 64비트 덤프를 분석하면, JVM이 왜 인터페이스 호출 시 클래스 상속보다 복잡한 과정을 거치는지 그 이유를 정확히 알 수 있습니다.
VTable 영역: 가상 메서드 (Index 0~6)
고정된 오프셋에 위치한 7개의 메서드 포인터입니다.
| 주소 | 데이터 | 정체 |
|---|---|---|
| 0x…f338 | 0x...2e001068 | Object.finalize() |
| 0x…f340 | 0x...2e0010c0 | Object.equals(Object) |
| 0x…f348 | 0x...2e001118 | Object.toString() |
| 0x…f350 | 0x...2e001170 | Object.hashCode() |
| 0x…f358 | 0x...2e0011d8 | Object.clone() |
| 0x…f360 | 0x...6f46c818 | SmartPhone.call() |
| 0x…f368 | 0x...6f46c8c8 | SmartPhone.takePhoto() |
ITable 영역: 인터페이스 주소록 (0x…f370 시작)
여기가 바로 핵심입니다. 인터페이스별로 어디에 어떤 메서드가 있는지 기록된 8워드의 공간입니다.
| 주소 | 데이터 | 정체 |
|---|---|---|
| 0x…f370 | 0x...2f0031f8 | Phone 인터페이스의 Klass 주소 |
| 0x…f378 | 0x00000228 | Phone 메서드 테이블이 시작되는 오프셋 |
| 0x…f380 | 0x...2f0033e8 | Camera 인터페이스의 Klass 주소 |
| 0x…f388 | 0x00000230 | Camera 메서드 테이블이 시작되는 오프셋 |
| 0x…f390 ~ f398 | 0x00000000 | 테이블의 끝을 알리는 Terminator |
위에서 지정한 오프셋 지점에 실제 구현체 주소가 들어있습니다.
| 주소 | 데이터 | 정체 |
|---|---|---|
0x…f3a0 (0xf178 + 0x228) | 0x...6f46c818 | SmartPhone.call의 실제 주소 |
0x…f3a8 (0xf178 + 0x230) | 0x...6f46c8c8 | SmartPhone.takePhoto의 실제 주소 |
이로써 이론과 물리적 실체가 일치함을 확인했습니다.
Case 7. 추상 클래스 상속
인터페이스와 유사하면서도 클래스의 성격을 동시에 갖는 ‘추상 클래스(Abstract Class)’ 상속 시의 메모리 동작을 해부합니다. 특히 구현체가 없는 추상 메서드가 VTable 상에서 어떻게 자리를 선점(Reservation)하며, 런타임에 이 미완성된 슬롯이 호출되는 사고를 JVM이 어떤 물리적 장치로 방어하는지 분석합니다.
모든 도형의 공통 속성인 color를 가지되, 그리는 방법은 결정되지 않은 추상 클래스 Graphic과, 이를 상속받아 draw() 메서드를 구체화한 Circle 클래스를 가정합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 추상 메서드의 VTable 슬롯 선점 및 자식 클래스의 오버라이딩 메커니즘
*/
public class AbstractClassAnatomy {
abstract static class Graphic {
int color = 0xFFFFFF; // 4B
// 추상 메서드: VTable에 슬롯은 생성되지만 주소는 Stub을 가리킴
abstract void draw();
void info() { System.out.println("Graphic color: " + color); }
}
static class Circle extends Graphic {
int radius = 10; // 4B
@Override
void draw() { System.out.println("Drawing Circle with radius " + radius); }
}
public static void main(String[] args) {
Graphic circle = new Circle();
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
// 1. 인스턴스 레이아웃 확인
System.out.println("=== [Circle 인스턴스의 메모리 맵 (Heap)] ===");
System.out.println(ClassLayout.parseInstance(circle).toPrintable());
// 2. 메타데이터 정보 출력
System.out.println("=== [클래스 설계도 정보] ===");
System.out.println("Circle은 부모 Graphic의 VTable 구조를 상속받아 draw() 슬롯을 재채웁니다.");
}
}
추상 클래스는 직접 인스턴스화할 수 없지만, 자식 클래스인 Circle이 생성될 때 그 메타데이터는 부모인 Graphic의 설계도를 충실히 반영합니다.
- VTable 슬롯의 선점: JVM은 부모인
Graphic클래스를 로딩할 때, 구현체가 없더라도draw()메서드를 위한 VTable 슬롯을 반드시 할당합니다. 추상 메서드 역시 해당 클래스 계층에서 반드시 존재해야 하는 ‘행위의 규격’이기 때문입니다. - 에러 핸들러 주소 바인딩: 구현되지 않은 추상 메서드 슬롯은 비어 있거나
null이 아닙니다. JVM은 이 자리에AbstractMethodError Stub이라 불리는 특수한 공통 루틴의 주소를 채워 넣습니다. 만약 잘못된 로직으로 인해 이 미완성 슬롯이 직접 호출되더라도, 시스템은 붕괴되지 않고 즉시 예외를 던져 스스로를 보호합니다. - 자식 클래스의 슬롯 업데이트 (Overwriting): 자식 클래스인
Circle이 로딩되어 자신의 VTable을 조립할 때, 부모로부터 물려받은draw()슬롯의 위치를 확인합니다. 이후 해당 슬롯의 내용을 기존의 에러 Stub 주소에서, 자신이 구체화한Circle.draw()의 실제 기계어 주소로 덮어씁니다.
이 메커니즘은 추상 클래스가 단순히 ‘개념적 존재’를 넘어, 메모리상에서 자식 클래스가 따라야 할 ‘물리적 레이아웃의 규격(Layout Specification)’을 강제하고 있음을 보여줍니다. 부모가 정해놓은 VTable의 순서와 필드 오프셋은 자식에게 그대로 전수되며, 자식은 오직 그 안의 ‘내용물(주소)’을 채울 권리만 가집니다.
추상 클래스 vs 인터페이스의 물리적 차이
추상 클래스는 VTable을 통해 메서드 위치를 고정할 수 있지만, 인터페이스는 앞서 보았듯 ITable을 통한 동적 탐색이 필요합니다. 따라서 성능 민감도가 극도로 높은 프레임워크 설계 시, 다중 구현이 필요 없는 상황이라면 인터페이스보다 추상 클래스를 사용하는 것이 VTable의 고정 인덱스 접근(Direct Access) 덕분에 미세하게 더 유리합니다.
Case 8. 익명 클래스와 람다
소스 코드상에서는 필드가 전혀 보이지 않는 익명 클래스(Anonymous Inner Class)나 람다(Lambda) 식을 분석합니다. 이러한 구조체들이 외부 클래스의 멤버나 지역 변수를 참조할 때, JVM이 어떻게 ‘합성 필드(Synthetic Field)’를 몰래 삽입하여 인스턴스의 크기를 키우는지, 그리고 이것이 왜 메모리 누수의 물리적 원인이 되는지 해부합니다.
외부 클래스 Button 내부에서 정의된 익명 Runnable 객체를 가정합니다. 이 익명 객체는 외부 클래스의 name 필드를 참조하고 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
import org.openjdk.jol.info.ClassLayout;
import org.openjdk.jol.vm.VM;
/**
* 익명 클래스의 hidden 필드(this$0) 및 변수 캡처로 인한 레이아웃 변화 실측
*/
public class AnonymousClassAnatomy {
static class Button {
String name = "SubmitButton";
public Runnable getListener() {
// 로컬 변수 캡처 대상 (상수 최적화 방지)
final String action = "CLICK".toLowerCase() + System.currentTimeMillis();
// 익명 클래스 생성: 외부의 name과 action을 참조함
return new Runnable() {
@Override
public void run() {
System.out.println(name + " performed " + action);
}
};
}
}
public static void main(String[] args) {
Button btn = new Button();
Runnable listener = btn.getListener();
System.out.println(VM.current().details());
System.out.println("----------------------------------\n");
// 1. 익명 클래스 인스턴스의 레이아웃 출력
System.out.println("=== [익명 Runnable 객체의 메모리 맵 (Heap)] ===");
System.out.println(ClassLayout.parseInstance(listener).toPrintable());
// 2. 외부 클래스 참조 필드(this$0) 존재 확인 안내
System.out.println("레이아웃 내부의 'this$0'는 Button 인스턴스를, ");
System.out.println("'val$action'은 로컬 변수 action을 가리키는 숨겨진 필드입니다.");
}
}
개발자 눈에는 메서드만 정의된 것처럼 보이지만, 컴파일된 바이트코드와 실제 힙 메모리 레이아웃은 전혀 다른 이야기를 합니다.
- 합성 필드의 강제 삽입: 외부 클래스의 인스턴스 멤버에 접근하기 위해, 컴파일러는 익명 클래스 내부에 외부 클래스의 주소를 담을
final참조 필드를 생성합니다. 이를 관례적으로this$0라고 부르며, 이 필드가 존재하는 한 익명 객체는 자신을 생성한 외부 객체와 물리적으로 연결됩니다. - 레이아웃의 비대화:
Runnable인터페이스를 구현한 익명 객체는 내부에 선언된 데이터 필드가 없으므로 12바이트(헤더)여야 할 것 같지만, 실제로는this$0필드가 4바이트(Compressed OOPs 기준)를 차지하여 총 16바이트의 인스턴스가 됩니다. - 변수 캡처(Variable Capture)와 상수 최적화:
- 메서드 내의 로컬 변수를 참조할 경우, 그 값을 복사해 두기 위한 별도의 필드(
val$variableName)가 추가로 생성되어 메모리를 더욱 점유합니다. - 단, 참조하는 변수가
final이거나 실질적final이면서 컴파일 타임에 값을 알 수 있는 ‘상수’인 경우, 컴파일러는 필드를 만드는 대신 값을 직접 치환(Substitution)하여 해당 필드를 생략하기도 합니다. - 런타임에 결정되는 동적인 값을 캡처할 때만 비로소
val$필드가 메모리 레이아웃에 명확히 드러나며 객체 크기를 키우게 됩니다.
- 메서드 내의 로컬 변수를 참조할 경우, 그 값을 복사해 두기 위한 별도의 필드(
이 메커니즘은 단순한 메모리 점유 이상의 문제를 야기합니다. 익명 클래스 인스턴스가 어딘가(예: 이벤트 큐, 캐시)에 남아 있는 한, 그 인스턴스가 가진 this$0 필드 때문에 외부 클래스 인스턴스 역시 가비지 컬렉터(GC)에 의해 수거되지 못합니다. 소스 코드에는 명시되지 않은 이 ‘물리적 참조’가 자바 메모리 누수의 가장 흔한 아키텍처적 원인입니다.
람다의 경우, 상태를 캡처하지 않는 ‘Stateless Lambda’라면 싱글톤처럼 재사용되어 오버헤드가 거의 없지만, 외부 변수를 참조하는 순간 익명 클래스와 유사하게 힙에 인스턴스를 생성하고 참조를 저장하는 비용을 치르게 됩니다. 결국 “편리한 추상화” 뒤에는 항상 “구체적인 바이트의 비용”이 숨어 있는 셈입니다.
Summary
JVM 인스턴스의 바이너리 레이아웃은 고수준의 객체 지향 추상화와 저수준의 하드웨어 효율성 사이에서 타협한 정교한 공학의 결과물입니다. 우리는 비트 단위로 압축된 헤더부터 8바이트 경계 정렬을 위한 패딩, 그리고 다형성을 뒷받침하는 VTable과 ITable의 물리적 실체를 확인했습니다. 이러한 하부 메커니즘을 이해하는 것은 단순한 지식을 넘어, 메모리 누수를 방지하고 CPU 캐시 효율을 극대화하는 고성능 시스템 설계의 토대가 됩니다. 결국 자바 객체는 논리적 개념이기 이전에, JVM 아키텍처가 하드웨어 성능을 끌어내기 위해 설계한 가장 최적화된 데이터 블록입니다.