[Computer Structure] CPU Cache와 False Sharing
현대의 CPU 클럭 속도는 기가헤르츠(GHz) 단위에 도달하여 나노초(ns) 미만의 간격으로 명령을 처리합니다. 반면 메인 메모리(DRAM)는 물리적 구조상의 한계로 인해 데이터 요청 후 응답까지 약 100ns 이상의 시간이 소요됩니다. 이 수백 배에 달하는 속도 격차를 메우기 위해, 하드웨어는 연산 장치와 메모리 사이에 SRAM 기반의 고속 저장소인 캐시를 계층적으로 배치합니다. 데이터는 이 계층을 거치며 각 층의 물리적 거리에 따른 지연 시간과 용량의 트레이드오프를 마주하게 됩니다.
🧩 Cache
데이터가 메모리로부터 CPU로 이동하는 여정의 최소 단위는 64바이트 캐시 라인(Cache Line)입니다. CPU는 단 1바이트의 데이터를 원하더라도 해당 주소를 포함한 64바이트 덩어리를 통째로 캐시로 가져옵니다. 이는 공간적 지역성(Spatial Locality)을 활용하여 이후 발생할 가능성이 높은 인접 데이터 요청을 미리 처리하기 위함입니다.
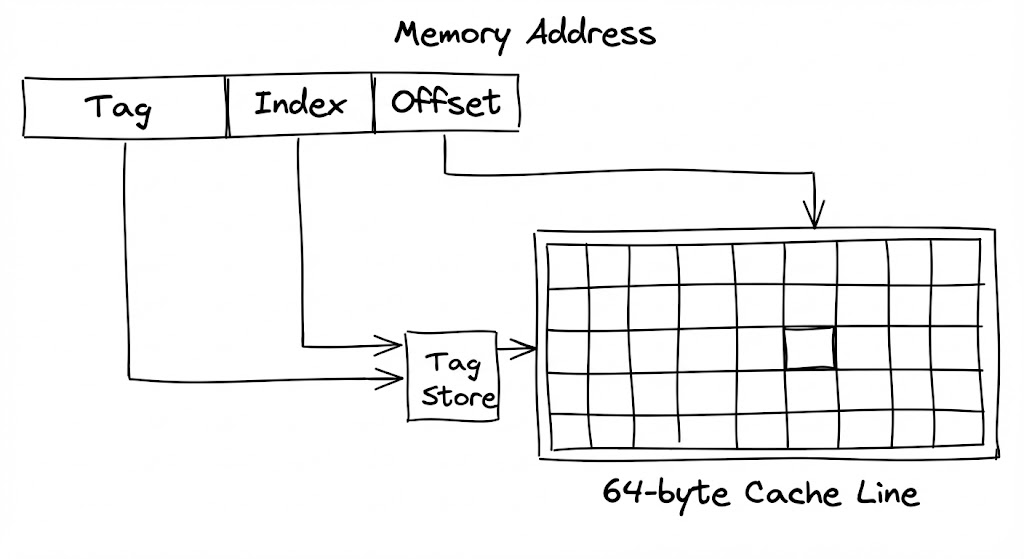
캐시 내에서 특정 주소의 존재 여부를 확인하는 과정은 하드웨어적 주소 분해를 통해 이루어집니다. 64비트 주소 체계는 태그(Tag), 인덱스(Index), 오프셋(Offset)으로 나뉘며, 인덱스 비트를 통해 캐시 내 특정 세트(Set)를 즉시 특정합니다. 이후 해당 세트 내의 여러 라인에 저장된 태그들과 요청된 주소의 태그를 병렬 회로로 대조하여 일치하는 지점을 찾아냅니다. 일치(Hit)가 발생하면 오프셋을 통해 64바이트 중 실제 필요한 데이터만 ALU로 전달하며, 이 모든 과정은 단 몇 사이클 내에 하드웨어 로직만으로 수행됩니다.
왜 하필 64바이트인가?
캐시 라인이 64바이트보다 작으면 태그 저장을 위한 메타데이터 오버헤드가 커지고, 너무 크면 한 번의 미스(Miss) 시 전송 지연이 길어지며 대역폭 낭비가 발생합니다. 64바이트는 버스 대역폭과 지역성 효율 사이의 최적 지점으로 설계된 규격입니다.
🧩 L1
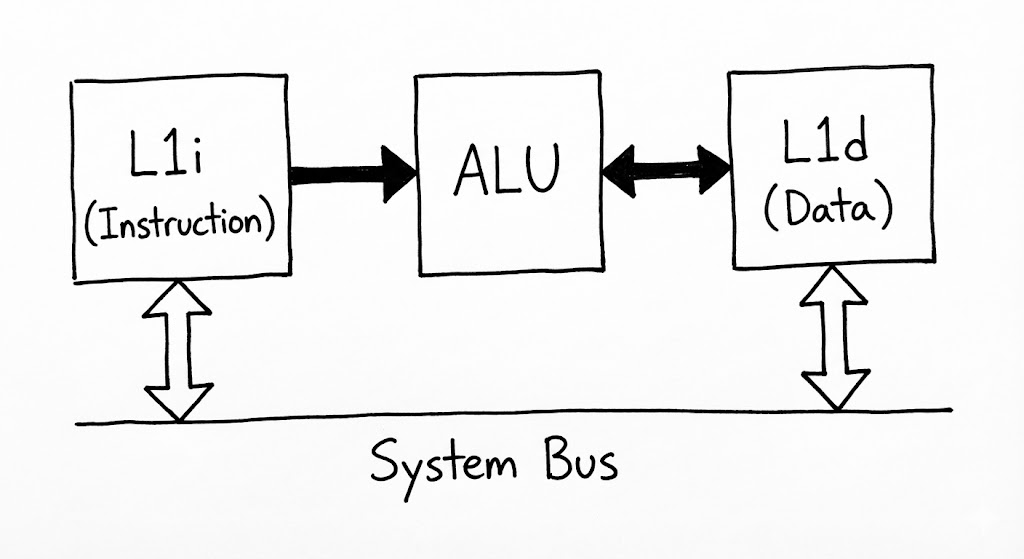
L1 캐시는 코어 내부의 연산 파이프라인과 직접 연결된 가장 빠르고 밀접한 저장소입니다. 물리적으로 ALU와 불과 수 마이크로미터 거리에 위치하여 빛의 이동 속도에 의한 지연조차 극소화합니다. L1은 명령어(Instruction)를 처리하는 L1i와 데이터(Data)를 처리하는 L1d로 나뉘어 존재합니다.
이러한 분리 구조는 파이프라인의 각 단계가 독립적으로 작동할 수 있게 합니다. CPU가 실행할 다음 명령어를 L1i에서 읽어오는 동안(Fetch), 현재 실행 중인 연산에 필요한 데이터는 L1d에서 읽어올 수 있습니다(Load). 만약 단일 통로였다면 자원 경합이 발생했겠지만, L1의 이원화된 설계는 매 사이클마다 끊김 없는 데이터 공급을 보장합니다. L1d에 기록된 연산 결과는 즉시 메모리로 전송되지 않고 캐시에 머물며, 나중에 한꺼번에 하위 계층으로 반영되는 쓰기 후 확산(Write-back) 방식을 채택하여 시스템 버스의 부하를 줄입니다.
- 병렬 인출: CPU 사이클이 시작되면 L1i에서 명령어를, L1d에서 피연산자를 동시에 탐색합니다.
- 단일 사이클 매칭: L1 컨트롤러는 주소 태그 매칭을 1~2사이클 내에 완료하고 데이터를 레지스터로 보냅니다.
- 연산 및 갱신: ALU 연산 결과는 먼저 L1d의 특정 캐시 라인에 기록되어 다음 연산에서 즉시 참조될 수 있도록 대기합니다.
🧩 L2
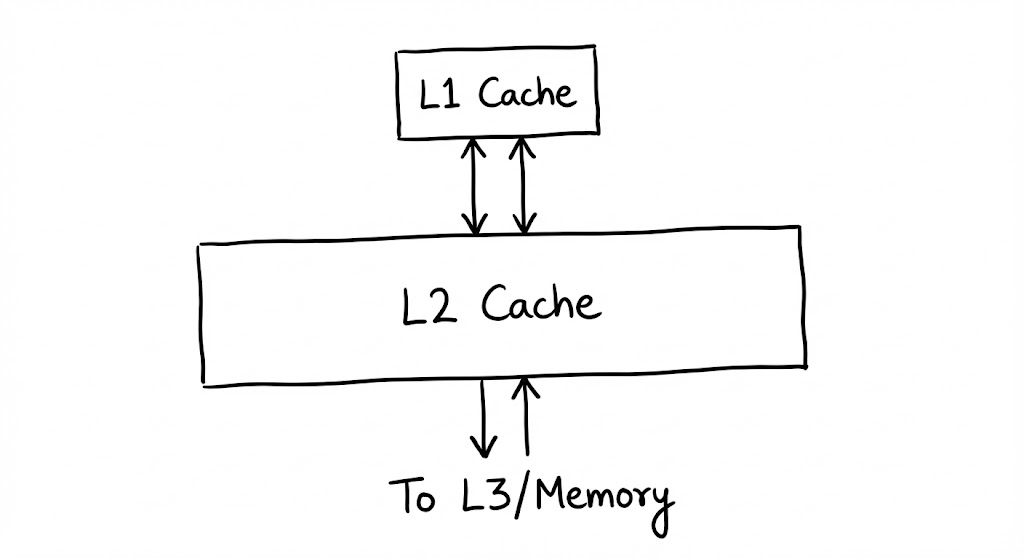
L1의 협소한 공간에서 밀려난 데이터들은 한 층 아래인 L2 캐시에 안착합니다. L2는 여전히 각 코어에 전용(Private)으로 할당된 공간이지만, 설계의 주안점은 ‘극단의 속도’에서 ‘L1의 빈번한 미스를 방어하기 위한 용량 확보’로 옮겨갑니다.
L2 캐시는 보통 $256\text{ KB}$에서 $1\text{ MB}$ 사이의 용량을 가집니다. L1보다 $8$배 이상 거대해진 SRAM 소자들을 배치하기 위해서는 더 넓은 물리적 면적이 필요하며, 이는 곧 연산 장치(ALU)로부터의 거리 증가와 배선 복잡도로 이어집니다. 이로 인해 L2 접근에는 약 $7\text{ ns}$에서 $12\text{ ns}$ 가량의 시간이 소요됩니다. 데이터의 관점에서는 L1에서 쫓겨난 뒤 RAM이라는 광야로 나가기 전 머무는 최후의 개인 대기실인 셈입니다.
L1 캐시 컨트롤러가 태그 매칭에 실패하면 즉시 L2로 요청이 전파됩니다. L2는 더 높은 연관도(Associativity)를 사용하여 주소 충돌을 방지하며 데이터를 탐색합니다. 여기서 데이터를 발견하면(Hit) 해당 캐시 라인은 다시 L1으로 복사되어 ‘승격’되며, CPU는 연산을 재개합니다. 만약 새로운 데이터가 들어올 자리가 없다면, 하드웨어는 LRU 알고리즘을 통해 가장 가치가 낮은 라인을 골라 하위 계층인 L3로 밀어냅니다.
Inclusive vs Exclusive: 어떤 설계가 더 유리한가?
상위 계층(L1)의 데이터를 하위 계층(L2)이 모두 포함하느냐(Inclusive), 아니면 쫓겨난 데이터만 보관하느냐(Exclusive)는 실리콘 공간 효율의 핵심 트레이드오프입니다. 현대 아키텍처는 주로 중복을 최소화하여 유효 용량을 늘리는 비포함(Non-inclusive) 방식을 선호합니다.
🧩 L3
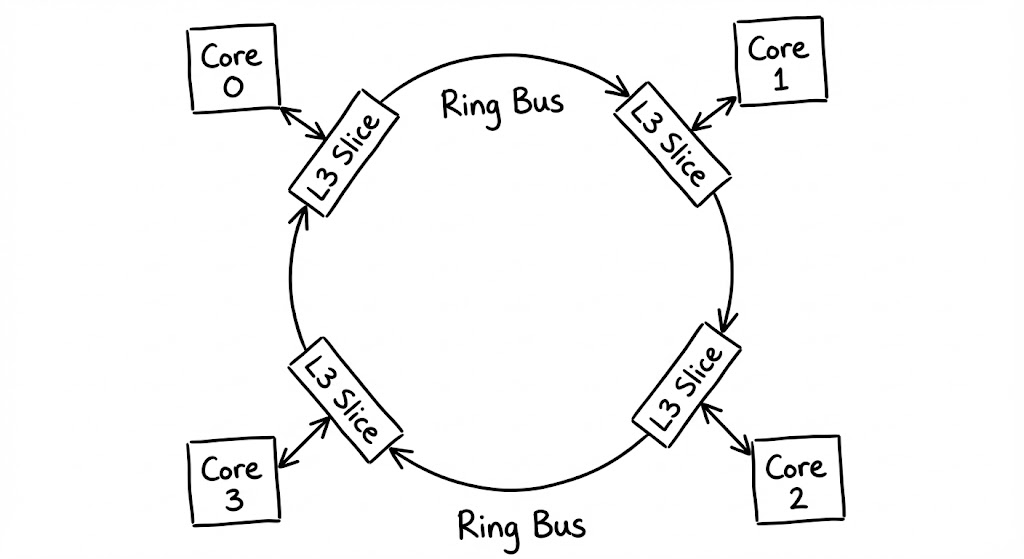
데이터가 개별 코어의 경계를 넘어 도달하는 L3 캐시는 모든 코어가 자원을 나누어 쓰는 중앙 광장입니다. 이곳은 더 이상 개인의 속도를 위한 공간이 아니라, 시스템 전체의 효율과 데이터 일관성을 조율하는 최후 수준 캐시(LLC, Last Level Cache)로 기능합니다.
L3는 수십 $\text{MB}$에 달하는 거대한 용량을 처리하기 위해 여러 개의 슬라이스(Slices)로 나뉘어 다이(Die) 전체에 분산 배치됩니다. 각 코어와 이 슬라이스들은 링 버스(Ring Bus)나 메시(Mesh) 구조의 고속 내부 네트워크로 연결됩니다. 데이터 패킷은 이 도로를 따라 순환하며 자신이 할당된 슬라이스를 찾아갑니다. L3의 지연 시간은 약 $30\text{ ns}$에서 $50\text{ ns}$ 수준으로 늘어나지만, 여전히 $100\text{ ns}$가 넘는 메인 메모리에 비하면 압도적으로 효율적인 완충 작용을 수행합니다.
- 글로벌 쿼리: 코어가 자신의 L2에서 실패한 주소를 링 버스에 태워 보내면, 해시 함수에 의해 지정된 L3 슬라이스가 이를 수신합니다.
- 일관성 중재: L3는 데이터를 내주기 전, 다른 코어의 전용 캐시(L1, L2)에 해당 데이터의 수정본이 있는지 먼저 확인하여 ‘가장 최신의 진실’을 확보합니다.
- 메모리 버스 인터페이스: L3의 모든 슬라이스에서도 데이터를 찾지 못할 경우에만, 비로소 외부 메모리 컨트롤러를 활성화하여 외부 RAM 접근 프로세스를 시작합니다.
왜 L3는 코어마다 따로 두지 않고 공유하는가?
데이터 공유가 빈번한 멀티코어 환경에서 각자 캐시를 크게 가지면 데이터 중복으로 인한 공간 낭비와 일관성 유지 비용이 폭증합니다. L3를 공유 공간으로 설계함으로써, 코어들은 서로의 데이터를 빠르게 복사해갈 수 있고 메모리 접근 횟수를 전사적으로 줄일 수 있습니다.
MESI Protocol
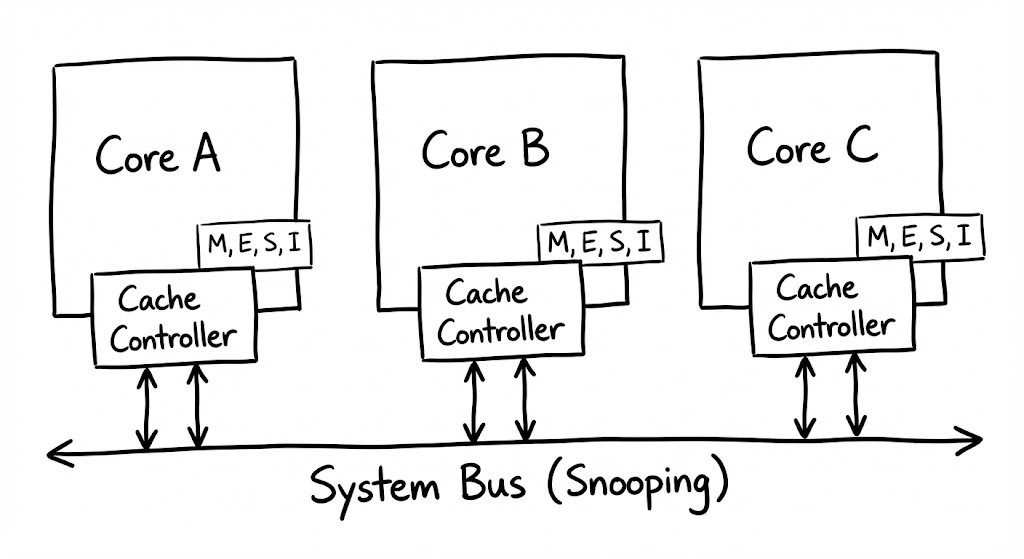
데이터가 각 코어의 전용 캐시(L1, L2)에 복제되어 존재하는 멀티코어 환경에서는 “누가 최신 데이터를 가지고 있는가?”라는 신뢰의 문제가 발생합니다. 하드웨어는 이 혼란을 해결하기 위해 각 캐시 라인의 상태를 추적하고 제어하는 MESI 프로토콜을 수행합니다.
여러 코어는 어떻게 하나의 진실에 합의하는가
이 합의의 핵심은 모든 코어의 캐시 컨트롤러에 탑재된 스누핑(Snooping) 로직에 있습니다. 각 코어는 시스템 버스나 상호 연결망(Interconnect)을 통해 흐르는 다른 코어의 메모리 요청 신호를 끊임없이 감시합니다. 특정 코어가 자신이 가진 데이터를 수정하려 한다는 신호를 보내면, 이를 엿듣고 있던 다른 코어들은 즉시 자신의 캐시에 있는 해당 데이터를 폐기하거나 업데이트할 준비를 합니다.
캐시 라인은 다음 네 가지 상태 중 하나로 표시되며, 이 상태는 전송되는 신호에 따라 유기적으로 변화합니다.
- Modified(M): 해당 코어가 데이터를 수정하여 RAM의 내용과 달라진 상태입니다. 이제 이 코어는 데이터의 유일한 주인이며, 다른 코어가 요청하면 최신본을 건네줄 의무가 생깁니다.
- Exclusive(E): 현재 이 코어만 데이터를 가지고 있지만, 아직 수정은 하지 않아 RAM과 데이터가 일치하는 상태입니다.
- Shared(S): 여러 코어가 동일한 데이터를 읽기 전용으로 나누어 가진 상태입니다. 누구든 데이터를 수정하려면 다른 코어들에게 먼저 알려야 합니다.
- Invalid(I): 다른 코어가 데이터를 수정했기 때문에, 내 캐시에 있는 데이터는 더 이상 사용할 수 없는 쓰레기가 된 상태입니다.
데이터 일관성을 위한 숨겨진 비용
MESI 프로토콜은 데이터 정합성을 완벽히 보장하지만, 상태를 변경할 때마다 버스에 신호를 뿌리고 다른 코어의 응답을 기다리는 통신 비용이 발생합니다. 코어 수가 늘어날수록 이 ‘합의’를 위한 트래픽이 기하급수적으로 증가하며 전체 성능의 발목을 잡기도 합니다.
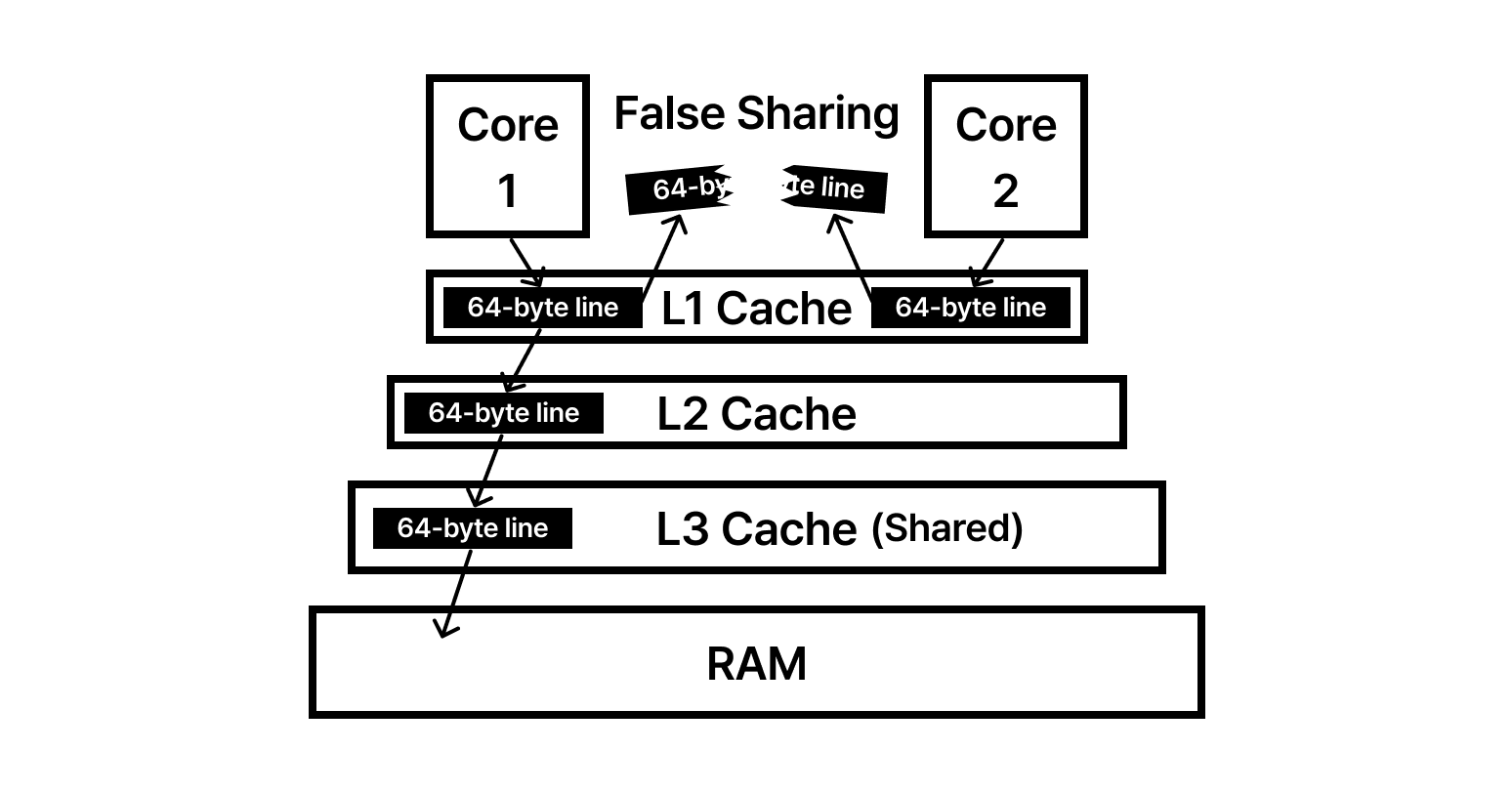
🧩 False Sharing
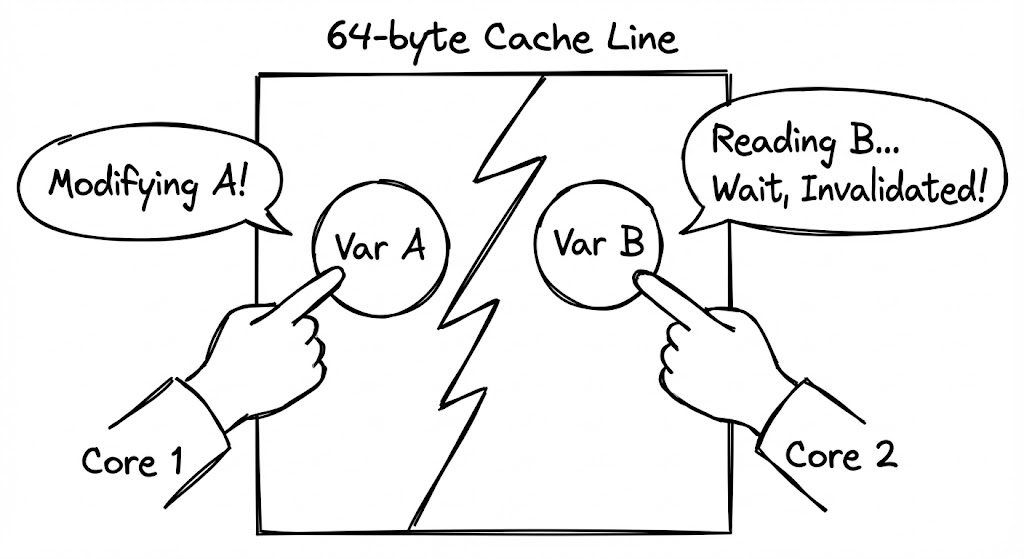
앞서 다룬 $64\text{ bytes}$ 캐시 라인 규격과 MESI 프로토콜이 멀티코어 환경에서 최악의 시너지를 내는 지점이 바로 가짜 공유(False Sharing)입니다. 이는 논리적으로는 완벽하게 독립된 코드가 물리적인 배치 때문에 서로를 방해하는 현상입니다.
독립적인 데이터가 왜 서로 충돌하는가
하드웨어는 소유권을 관리할 때 바이트 단위가 아닌 $64\text{ bytes}$ 덩어리 전체를 하나의 단위로 취급합니다. 만약 두 스레드가 서로 다른 변수(var A, var B)를 수정하려는데, 이 두 변수가 우연히 메모리상에서 인접하여 같은 $64\text{ bytes}$ 라인 안에 묶여 있다면 비극이 시작됩니다.
코어 1이 var A를 수정하는 순간, MESI 프로토콜에 의해 해당 캐시 라인 전체가 코어 1의 독점 소유(Modified)가 됩니다. 이때 var B를 수정하려던 코어 2의 캐시 라인은 졸지에 Invalid 상태로 변해버립니다. 코어 2는 var A에는 관심조차 없었지만, 같은 ‘봉투’에 담겨 있었다는 이유만으로 자신의 데이터를 잃고 다시 메모리 계층을 뒤져 데이터를 가져와야 합니다.
- 동시 점유: 두 코어가 같은 캐시 라인을 Shared 상태로 로드합니다.
- 무효화 공격: 코어 1이 자신의 데이터를 수정하며 라인 전체의 소유권을 뺏어옵니다.
- 강제 미스: 코어 2는 멀쩡하던 자신의 데이터를 사용하려다 ‘캐시 미스’를 겪고 L3나 RAM으로 향합니다.
- 핑퐁 현상: 이제 코어 2가 소유권을 뺏어오면 코어 1이 미스를 겪습니다. 두 코어는 연산 대신 소유권 전쟁에 모든 시간을 허비합니다.
보이지 않는 성능 살인마
가짜 공유는 코드상에 명시적인 잠금(Lock)이나 경합이 없기 때문에 발견하기 매우 어렵습니다. 프로그램이 이유 없이 단일 스레드보다 느려지거나, 코어 수를 늘릴수록 성능이 떨어진다면 물리적 데이터 배치를 의심해야 합니다.
Padding과 Alignment
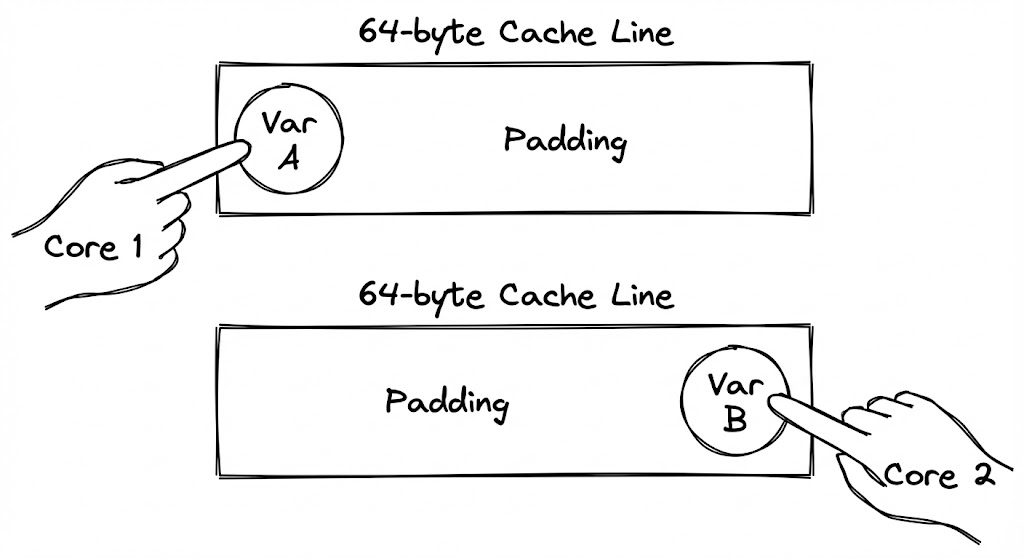
가짜 공유(False Sharing)가 하드웨어의 $64\text{-byte}$ 규격과 소프트웨어의 인접한 데이터 배치가 충돌하여 발생한다면, 해결책은 명확합니다. 두 데이터를 물리적으로 멀리 떨어뜨려 서로 다른 ‘봉투(Cache Line)’에 담기게 만드는 것입니다.
왜 일부러 메모리를 낭비하는가?
엔지니어는 가급적 메모리를 아껴 써야 한다는 본능을 가지고 있습니다. 하지만 멀티코어 환경에서는 이 본능이 오히려 성능을 파괴합니다. 가짜 공유를 해결하는 가장 확실한 방법은 변수 사이에 아무런 의미 없는 ‘더미 데이터’를 끼워 넣는 패딩(Padding) 기법입니다.
예를 들어, 두 개의 카운터 변수가 하나의 구조체에 있다면, 그 사이에 $64\text{ bytes}$ 크기의 빈 공간을 강제로 할당합니다. 이렇게 하면 첫 번째 변수와 두 번째 변수는 절대로 같은 캐시 라인에 머물 수 없게 됩니다. 메모리 공간은 수십 바이트 낭비되지만, 코어 간의 소유권 쟁탈전(Ping-pong)이 사라지면서 얻는 성능 이득은 그 비용을 압도하고도 남습니다.
하드웨어 제약에 소프트웨어를 정렬하기
단순히 공간을 띄우는 것만큼 중요한 것이 메모리 정렬(Alignment)입니다. 구조체의 시작 주소가 $64$의 배수가 아니라면, 아무리 패딩을 넣어도 변수가 캐시 라인 경계에 걸쳐버려 두 개의 라인을 동시에 점유하는 최악의 상황이 발생할 수 있습니다. 현대 언어들은
alignas(64)와 같은 지시어를 통해 데이터의 시작점을 캐시 라인 경계에 강제로 맞추는 기능을 제공합니다.
성능 최적화를 위한 3단계 접근법
멀티코어 성능 병목을 해결하기 위해 엔지니어는 다음의 순서로 하드웨어와의 교감을 시도합니다.
- 데이터 격리: 병렬로 수정되는 데이터들을 구조체 내에서 최대한 멀리 배치하거나, 별도의 객체로 분리합니다.
- 명시적 패딩 삽입: 언어별 특성에 맞게 더미 필드(예:
_ [56]byte)를 추가하여 강제로 캐시 라인을 분리합니다. - 컴파일러 힌트 활용: Java의
@Contended나 C++의alignas와 같이 하드웨어 아키텍처를 인지하는 컴파일러 지시어를 사용하여 자동 최적화를 유도합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
#include <iostream>
#include <thread>
#include <atomic>
#include <new> // std::hardware_destructive_interference_size
/**
* [최적화 포인트]
* 1. alignas: 구조체나 변수의 시작 주소를 특정 바이트 경계(여기서는 64바이트)로 맞춥니다.
* 2. hardware_destructive_interference_size: 플랫폼별 캐시 라인 크기를 반환하는 상수입니다.
* (지원되지 않는 환경을 위해 보통 64바이트를 기본값으로 사용합니다.)
*/
#ifdef __cpp_lib_hardware_interference_size
using std::hardware_destructive_interference_size;
#else
// 일반적인 x86/ARM 아키텍처의 캐시 라인 크기인 64바이트를 사용
constexpr std::size_t hardware_destructive_interference_size = 64;
#endif
// 1. 가짜 공유가 발생하는 구조체
struct CriticalData {
std::atomic<uint64_t> counterA; // 코어 1이 주로 수정
std::atomic<uint64_t> counterB; // 코어 2가 주로 수정
};
// 2. 패딩과 정렬을 통해 가짜 공유를 제거한 구조체
struct OptimizedData {
// counterA를 캐시 라인 시작점에 정렬
alignas(hardware_destructive_interference_size) std::atomic<uint64_t> counterA;
// counterA와 counterB 사이에 캐시 라인 크기만큼의 간격을 강제로 생성
// 이를 통해 두 변수는 물리적으로 같은 캐시 라인에 담길 수 없음
alignas(hardware_destructive_interference_size) std::atomic<uint64_t> counterB;
};
void run_test() {
OptimizedData data;
std::cout << "--- Memory Layout Analysis ---" << std::endl;
std::cout << "Address of A: " << &data.counterA << std::endl;
std::cout << "Address of B: " << &data.counterB << std::endl;
// 두 주소의 차이가 64바이트 이상임을 확인
size_t distance = reinterpret_cast<uintptr_t>(&data.counterB) -
reinterpret_cast<uintptr_t>(&data.counterA);
std::cout << "Distance between A and B: " << distance << " bytes" << std::endl;
if (distance >= hardware_destructive_interference_size) {
std::cout << "Result: False Sharing is successfully prevented." << std::endl;
}
}
int main() {
run_test();
return 0;
}
Summary
독립된 두 변수 A와 B가 우연히 동일한 $64\text{-byte}$ 캐시 라인에 놓인 상태에서, 코어 1은 A를, 코어 2는 B를 반복 수정하는 가짜 공유(False Sharing) 상황에서의 데이터 프로세스를 다음과 같이 정리합니다.
- 상태 공유(Initial Loading): 코어 1과 코어 2가 메모리에서 데이터를 읽어와 각각의 전용 캐시(L1/L2)에 적재합니다. 이때 두 코어의 캐시 라인 상태는 Shared(S)가 됩니다.
- 수정 및 무효화 전파(Invalidation): 코어 1이 변수
A를 수정하기 위해 상호 연결망(Bus)에 무효화(Invalidate) 신호를 전송합니다. 이 신호를 수신한 코어 2의 캐시 컨트롤러는 해당 라인을 즉시 Invalid(I) 상태로 전환합니다. - 독점적 상태 전환(Exclusivity): 코어 1의 캐시 라인 상태는 Modified(M)가 되며, 해당 라인에 대한 유일한 최신 데이터 소유권을 획득합니다.
- 강제 캐시 미스 발생(Forced Miss): 코어 2가 변수
B를 읽으려 할 때, 비록B값 자체는 변경되지 않았으나 라인 전체가 무효화되었으므로 캐시 미스가 발생합니다. 코어 2는 코어 1의 캐시 혹은 하위 계층으로부터 데이터를 다시 가져와야 합니다. - 성능 하락(Ping-pong): 코어 2가 다시 변수를 수정하면 코어 1의 라인이 무효화되는 과정이 반복됩니다. 이 과정에서 발생하는 버스 트래픽과 동기화 지연으로 인해 CPU의 연산 자원이 낭비되며 병렬 처리 효율이 급격히 저하됩니다.