[Distributed System] CAP와 PACELC 이론
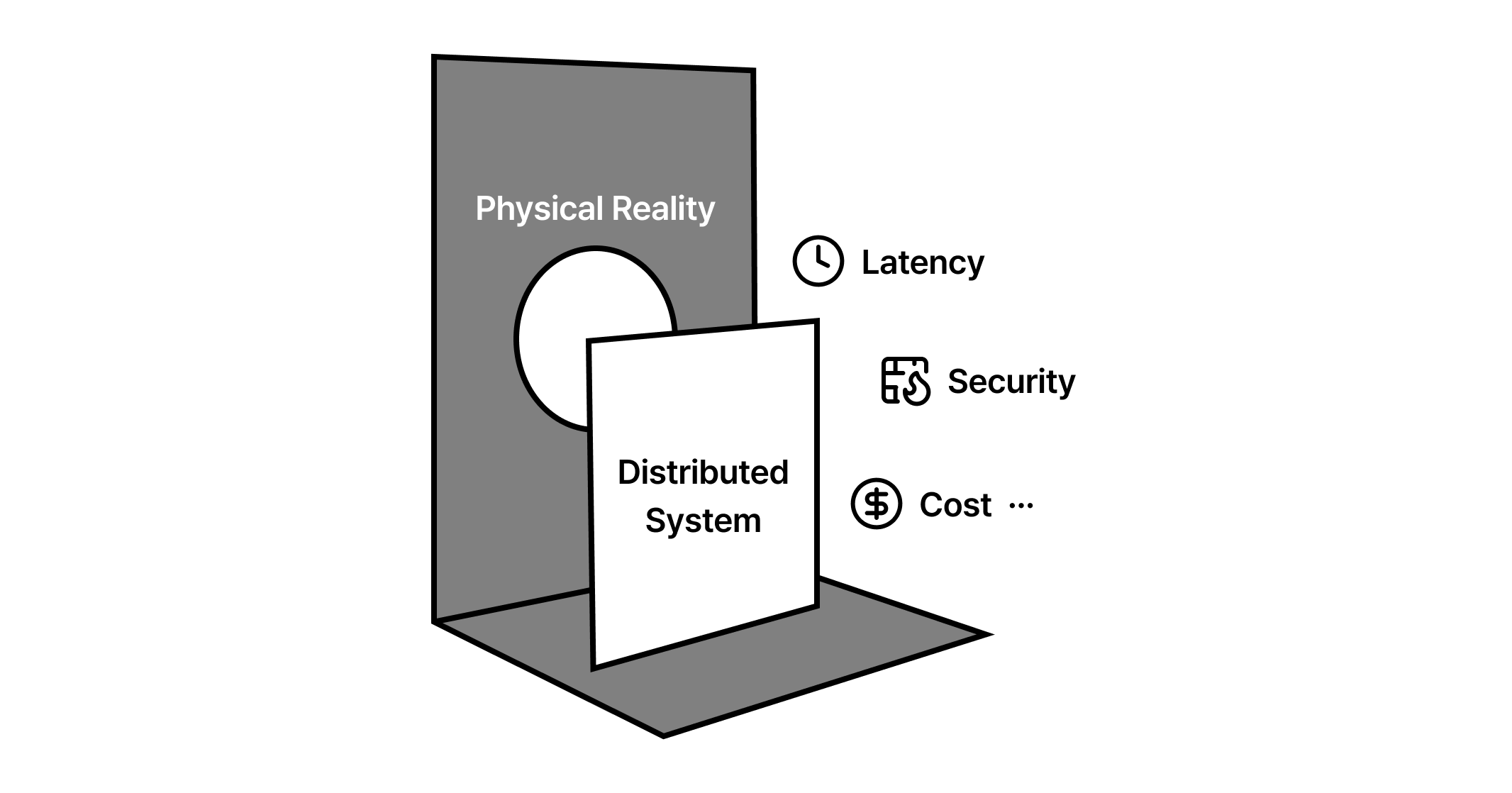
엔지니어링의 역사는 추상화와의 끊임없는 사투였습니다. 우리는 복잡한 하드웨어의 동작을 운영체제라는 인터페이스 뒤로 숨겼고, 이제는 전 세계에 흩어진 수천 대의 서버를 마치 하나의 거대한 컴퓨터처럼 다루려 시도합니다. 그러나 로컬 함수 호출과 원격 프로시저 호출(RPC) 사이의 간극을 메우려는 이 대담한 시도는 종종 비참한 실패로 끝납니다.
이 실패의 중심에는 ‘물리적 실체’를 무시한 소프트웨어적 낙관주의가 자리 잡고 있습니다. 분산 시스템을 설계한다는 것은 단순히 여러 대의 서버에 코드를 배포하는 행위가 아닙니다. 그것은 빛의 속도가 유한하고, 구리선과 광섬유가 언제든 끊어질 수 있으며, 네트워크 패킷이 블랙홀로 사라질 수 있다는 가혹한 현실을 인정하는 것에서부터 시작됩니다. 분산 컴퓨팅의 유토피아를 꿈꾸기 전에, 우리가 발을 딛고 있는 이 불확실한 토양의 정체를 먼저 파헤쳐야 합니다.
🧩 The 8 Fallacies
1994년, Sun Microsystems의 Peter Deutsch와 동료들은 분산 시스템을 처음 접하는 엔지니어들이 공통적으로 저지르는 8가지 오해를 정의했습니다. 수십 년이 흐른 지금, 인프라는 클라우드로 옮겨갔고 컨테이너 기술은 고도화되었지만, 이 8가지 오류는 여전히 분산 아키텍처를 무너뜨리는 가장 강력한 변수로 작동합니다.
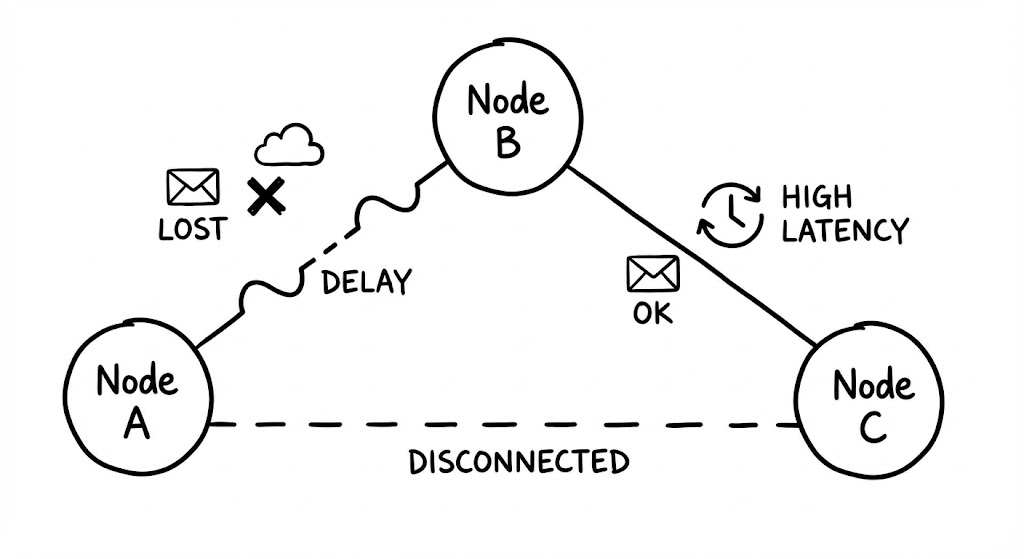
❌ 1. 네트워크는 신뢰할 수 있다
가장 기초적이면서도 파괴적인 오해입니다. 로컬 시스템에서의 메모리 접근은 하드웨어 결함이 없는 한 성공을 보장하지만, 네트워크는 본질적으로 ‘최선(Best-effort)’만을 다할 뿐입니다. 스위치의 오작동, 누군가 실수로 건드린 광케이블, 혹은 과부하로 인한 패킷 드랍은 일상적인 이벤트입니다.
엔지니어가 네트워크를 신뢰하는 순간, 시스템은 예외 처리가 없는 취약한 상태가 됩니다. 이를 극복하기 위해 도입하는 ‘재시도(Retry)’ 메커니즘은 양날의 검입니다. 네트워크 일시 장애 시 단순 재시도는 유효하지만, 대상 서버가 과부하 상태일 때 무분별한 재시도는 ‘재시도 폭풍(Retry Storm)’을 일으켜 전체 시스템을 마비시킵니다. 따라서 지수 백오프(Exponential Backoff)와 지터(Jitter)를 결합한 정교한 재시도 전략은 선택이 아닌 필수입니다.
❌ 2. 지연 시간은 0이다
로컬 함수 호출의 지연 시간은 나노초(ns) 단위인 반면, 네트워크를 통한 호출은 밀리초(ms) 단위로 측정됩니다. 이는 최소 수만 배에서 수백만 배의 차이입니다. 빛의 속도는 초당 약 30만 킬로미터라는 물리적 한계를 가지며, 서울에서 뉴욕까지 패킷이 왕복하는 데만 최소 150ms 이상이 소요됩니다.
‘지연 시간은 0’이라는 착각은 서비스 간의 빈번한 통신(Chatty API)을 유발합니다. 작은 데이터를 주고받는 수백 번의 호출은 전체 응답 시간을 기하급수적으로 늘리며, 사용자 경험을 훼손합니다. 현대의 분산 시스템 설계자는 데이터의 지역성(Locality)을 고려하고, 가능한 한 호출 횟수를 줄이는 벌크 처리나 비동기 메시징을 고민해야 합니다.
❌ 3. 대역폭은 무한하다
광섬유 기술의 발전으로 대역폭이 비약적으로 증가했음에도 불구하고, 대역폭은 여전히 유한한 자원입니다. 특히 마이크로서비스 아키텍처(MSA)에서는 서비스 간 이동하는 트래픽의 총량이 단일 모놀리스 구조보다 훨씬 큽니다.
대역폭이 무한하다고 가정하면 무거운 페이로드를 아무런 거리낌 없이 전송하게 됩니다. 이는 네트워크 인터페이스 카드(NIC)의 병목을 유발할 뿐만 아니라, 패킷을 처리하는 CPU 자원의 고갈로 이어집니다. 대역폭 한계에 도달하면 패킷 큐잉(Queuing)이 발생하고, 이는 곧 지연 시간의 급격한 상승으로 이어지는 연쇄 작용을 일으킵니다.
❌ 4. 네트워크는 보안상 안전하다
과거에는 사내 망(Intranet)에만 접속하면 안전하다는 ‘경계 보안’ 개념이 지배적이었습니다. 하지만 현대의 분산 시스템은 공용 인터넷과 복잡하게 얽혀 있으며, 내부자 공격이나 설정 오류로 인한 유출 위협에 상시 노출되어 있습니다.
네트워크가 안전하다는 가정은 암호화되지 않은 평문 통신을 허용하는 치명적인 결과를 초래합니다. 현대 엔지니어링의 정석은 ‘Zero Trust’입니다. 모든 네트워크 호출은 잠재적으로 위험하다고 가정하고, 상호 TLS(mTLS)를 통한 인증과 암호화를 기본으로 채택해야 합니다.
❌ 5. 토폴로지는 변하지 않는다
서버의 IP가 고정되어 있고 네트워크 구성이 정적이었던 시대는 끝났습니다. 쿠버네티스(Kubernetes) 환경에서 파드(Pod)는 수초 만에 생성되고 소멸하며, IP 주소는 끊임없이 변합니다.
토폴로지가 고정되어 있다고 믿는 설계는 하드코딩된 설정 파일에 의존하게 만들고, 이는 시스템의 유연성을 완전히 박살 냅니다. 현대 시스템은 서비스 디스커버리(Service Discovery) 메커니즘을 통해 동적으로 변화하는 네트워크 지형을 실시간으로 반영할 수 있어야 합니다.
❌ 6. 관리자는 한 명이다
분산 시스템의 규모가 커질수록 이를 관리하는 주체는 파편화됩니다. 플랫폼 팀, 보안 팀, 각 서비스의 개발 팀이 서로 다른 영역을 담당합니다.
‘한 명의 전지전능한 관리자’가 존재한다는 착각은 설정의 일관성이 유지될 것이라는 믿음을 낳습니다. 그러나 실제로는 서비스 A의 타임아웃 설정과 서비스 B의 처리 시간이 맞지 않아 장애가 발생하거나, 특정 팀의 방화벽 설정 변경이 전체 서비스의 단절을 가져오는 경우가 허다합니다. 거버넌스의 분산은 필연적이며, 이를 자동화된 정책 관리와 모니터링으로 보완해야 합니다.
❌ 7. 운송 비용은 0이다
데이터를 네트워크로 보내는 데는 물리적인 비용이 발생합니다. 단순히 클라우드 제공업체가 부과하는 네트워크 출구 비용(Egress Cost)만을 의미하는 것이 아닙니다.
데이터를 전송하기 위해 객체를 직렬화(Serialization)하고, 수신 측에서 다시 역직렬화하는 데 소모되는 CPU와 메모리 자원은 결코 무시할 수 없는 수준입니다. 특히 고성능 시스템에서는 이 비용을 줄이기 위해 JSON 대신 프로토콜 버퍼(Protocol Buffers)나 Avro 같은 효율적인 바이너리 포맷을 선택하는 치열한 최적화 과정이 수반됩니다.
❌ 8. 네트워크는 균일하다
모든 노드가 동일한 운영체제, 동일한 프로토콜, 동일한 하드웨어를 사용할 것이라는 가정은 위험합니다. 현대의 네트워크는 다양한 벤더의 장비와 서로 다른 버전의 소프트웨어가 뒤섞인 ‘이종(Heterogeneous)’ 환경입니다.
프로토콜의 미묘한 구현 차이, 엔디언(Endianness) 문제, 혹은 지원하는 암호화 알고리즘의 불일치 등은 예기치 않은 지점에서 시스템을 중단시킵니다. 표준 프로토콜을 준수하고 상호운용성(Interoperability)을 철저히 검증하는 태도가 필요한 이유입니다.
🧩 CAP Theorem
분산 시스템의 세계에서 Eric Brewer가 제시한 CAP 이론은 물리학의 열역학 법칙과 같은 위상을 가집니다. 이는 단순히 “세 가지 중 두 가지를 선택하라”는 마케팅 문구가 아니라, 네트워크라는 불안정한 매체 위에서 데이터의 정합성을 유지하려는 모든 엔지니어가 마주해야 하는 근본적인 한계선입니다.
분산 시스템의 삼자택일
CAP 이론은 일관성(Consistency), 가용성(Availability), 분단 허용성(Partition Tolerance)이라는 세 가지 가치가 동시에 완벽하게 충족될 수 없음을 증명합니다. 여기서 각 용어는 분산 시스템 특유의 엄격한 정의를 가집니다.
CAP의 세부 정의
- Consistency (일관성): 모든 노드가 같은 시간에 같은 데이터를 보아야 합니다. 즉, 어떤 노드로 읽기 요청을 보내든 가장 최근에 쓰여진 데이터를 반환받거나, 혹은 에러를 반환받아야 함을 의미합니다. (선형 일관성, Linearizability)
- Availability (가용성): 모든 요청은 성공 또는 실패 여부와 상관없이 ‘응답’을 받아야 합니다. 특정 노드에 장애가 나더라도 시스템 전체는 가동되어야 하며, 일관성을 보장하지 못하더라도 일단 답은 주어야 합니다.
- Partition Tolerance (분단 허용성): 노드 간의 통신망이 끊기거나 패킷이 손실되는 ‘네트워크 분단’ 상황에서도 시스템이 중단되지 않고 제 기능을 수행해야 함을 의미합니다.
많은 이들이 CAP를 “C, A, P 중 2개를 고르는 게임”으로 오해하곤 합니다. 하지만 네트워크를 통해 연결된 분산 시스템에서 ‘P(분단 허용성)’를 포기한다는 것은 네트워크 고장이 발생했을 때 시스템 전체가 중단되어도 좋다는 선언과 같습니다. 즉, 분산 시스템에서 P는 ‘선택’이 아닌 ‘상수’입니다.
P의 필연성과 강제된 선택
분산 컴퓨팅의 8가지 오류에서 확인했듯, 네트워크는 반드시 실패합니다. 따라서 실제 엔지니어링의 선택지는 CA(Consistency + Availability)가 아니라, 네트워크 분단(P)이 발생했을 때 C를 택할 것인가 A를 택할 것인가로 좁혀집니다.
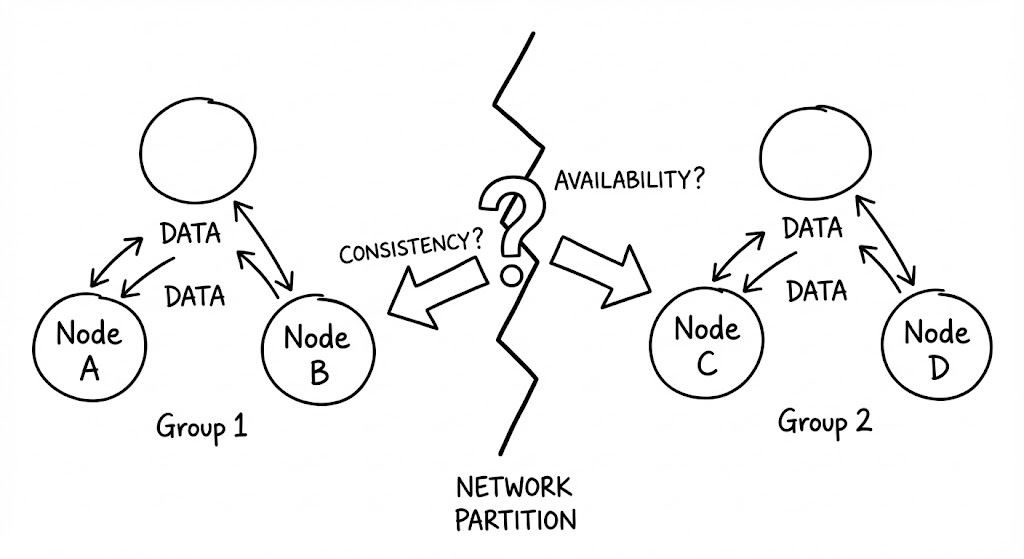
네트워크가 정상일 때는 일관성과 가용성을 모두 누릴 수 있습니다. 그러나 두 노드 사이의 연결이 끊어지는 순간(Partition), 시스템은 외통수에 몰립니다.
- C를 선택하는 경우 (Consistency over Availability): 데이터의 최신성을 보장할 수 없다면 차라리 응답을 거부합니다. 이는 시스템의 일부 기능을 마비시키더라도 데이터 오염을 막겠다는 의지입니다.
- A를 선택하는 경우 (Availability over Consistency): 데이터가 비록 과거의 것일지라도(Stale Data), 일단 응답을 제공하여 서비스의 연속성을 유지합니다. 데이터의 일관성은 네트워크가 복구된 뒤에 해결(Eventual Consistency)하기로 미룹니다.
CP와 AP 아키텍처의 갈림길
어떤 선택이 ‘옳은가’에 대한 답은 없습니다. 오직 비즈니스 도메인의 특성에 따른 ‘트레이드오프’만이 존재할 뿐입니다.
- CP 시스템 (Consistency + Partition Tolerance): 금융 시스템이나 원자적 상태 관리가 필요한 분산 락(Distributed Lock) 서비스가 대표적입니다. Google Spanner나 HBase, MongoDB(기본 설정) 등은 데이터의 무결성이 깨지는 것보다 차라리 서비스가 잠시 불능 상태가 되는 것을 택합니다. 사용자가 잔액 조회에 실패하는 것은 불편한 일이지만, 잔액이 틀리게 표시되는 것은 치명적인 사고이기 때문입니다.
- AP 시스템 (Availability + Partition Tolerance): 쇼핑몰의 장바구니, SNS의 ‘좋아요’ 수, 뉴스 피드 등이 여기에 해당합니다. Cassandra, DynamoDB, CouchDB 등은 일부 노드 간 연결이 끊겨도 사용자에게 서비스를 계속 제공합니다. 장바구니에 담긴 물건이 잠시 안 보이거나 ‘좋아요’ 수가 조금 늦게 업데이트되더라도, 서비스 자체가 멈추는 것보다는 낫다는 판단입니다.
CA 시스템은 존재할 수 없는가?
이론적으로 단일 노드 데이터베이스(Single-node DB)는 네트워크 분단이 발생할 여지가 없으므로 강한 일관성과 가용성을 동시에 가질 수 있습니다. 하지만 이는 더 이상 ‘분산 시스템’이 아닙니다. 확장이 필요한 현대의 아키텍처에서 CA는 달성 불가능한 신기루에 가깝습니다.
이처럼 CAP 이론은 우리에게 냉혹한 현실을 일깨워줍니다. 완벽한 시스템은 없으며, 아키텍트는 분단이라는 위기 상황에서 무엇을 희생할지 결정해야 하는 ‘고독한 결정권자’가 되어야 합니다. 하지만 CAP 이론만으로는 설명되지 않는 더 깊은 영역이 존재합니다. 바로 네트워크 장애가 없는 ‘평상시’의 성능 문제입니다.
🧩 PACELC Theorem
CAP 이론은 분산 시스템의 ‘재난’ 상황을 다루는 훌륭한 나침반이지만, 현대의 고성능 아키텍처를 설명하기에는 부족함이 있습니다. 실제 운영 환경에서 네트워크 분단(P)은 매우 드물게 발생하며, 시스템 수명의 99.9%는 모든 노드가 연결된 ‘정상 상태(Normal operation)’이기 때문입니다. Daniel Abadi가 제안한 PACELC 이론은 CAP이 놓친 이 99.9%의 시간 동안 우리가 지불해야 하는 진짜 비용을 정의합니다.
정상 상태에서의 비용: 지연 시간
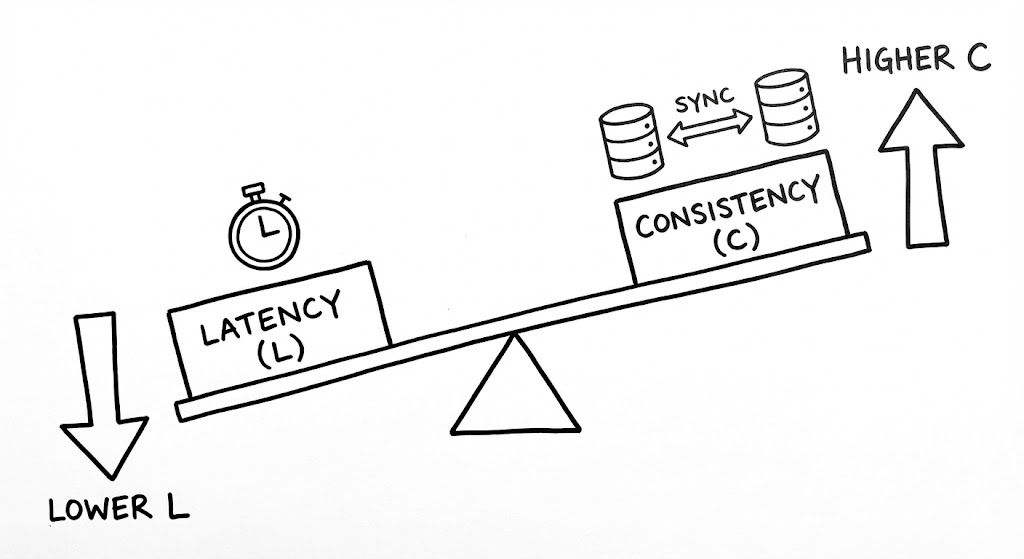
네트워크가 정상적일 때(Else), 우리는 CAP의 제약에서 벗어나 자유로울 것이라 착각하기 쉽습니다. 하지만 물리적 거리는 여전히 존재하며, 빛의 속도는 여전히 유한합니다. 모든 데이터 복제본이 최신 상태를 유지하도록 보장하려면(Consistency), 모든 노드의 확인 응답을 기다려야 합니다. 이는 필연적으로 응답 속도의 저하, 즉 지연 시간(Latency)의 증가를 초래합니다.
반대로 응답 속도를 극대화하려면(Latency), 다른 노드에 데이터가 전파되기를 기다리지 않고 클라이언트에게 즉시 답을 주어야 합니다. 이 경우 일부 클라이언트는 아주 잠깐이나마 과거의 데이터(Stale Data)를 읽게 될 위험을 감수해야 합니다. 즉, 평상시에도 우리는 ‘더 나은 성능’과 ‘더 정확한 데이터’ 사이에서 끊임없이 저울질을 하고 있는 셈입니다.
확장된 트레이드오프 모델
PACELC 이론은 CAP의 조건부 논리를 한 단계 확장하여, 시스템의 상태를 ‘장애’와 ‘정상’이라는 두 가지 국면으로 분리합니다. 이를 가장 명쾌하게 표현하는 것이 바로 If P, then (A or C), Else (L or C) 공식입니다. 이 수식은 분산 시스템이 마주하는 운명적인 선택을 프로그래밍 언어의 조건문처럼 정의합니다.
먼저 If Partition (P) 구간은 CAP 이론이 다루는 영역입니다. 네트워크 단절이라는 위기 상황이 닥쳤을 때, 시스템은 가용성(A)을 택해 낡은 데이터라도 줄 것인지, 아니면 일관성(C)을 택해 응답을 거부할 것인지 결정해야 합니다. 이는 ‘생존’의 문제입니다.
반면 Else (E) 구간은 시스템의 평상시 상태를 다룹니다. 네트워크가 안정적인 상황에서도 지연 시간(Latency)과 일관성(Consistency) 사이의 트레이드오프는 사라지지 않습니다. 모든 복제본에 데이터가 완벽히 기록될 때까지 클라이언트를 기다리게 할 것인지(C), 아니면 일단 빠르게 응답을 주고 배경에서 데이터를 동기화할 것인지(L)를 선택해야 합니다. 이는 ‘성능’의 문제입니다.
이 논리 구조에 따라 현대의 분산 데이터베이스는 다음과 같은 네 가지 주요 스펙트럼 위로 분류됩니다.
- PA/EL (Partition-Availability / Else-Latency): 장애 시 가용성을 보장하고, 평상시에는 극도의 저지연 성능을 지향합니다. DynamoDB와 Cassandra가 대표적이며, ‘빠른 응답’이 비즈니스의 핵심인 대규모 서비스에서 가장 선호되는 전략입니다.
- PC/EC (Partition-Consistency / Else-Consistency): 어떤 상황에서도 데이터 무결성을 최우선으로 합니다. Google Spanner와 같이 금융 거래나 원자적 연산이 필수적인 시스템은 장애 시 응답을 포기하고, 평시에도 동기화 비용(Latency)을 지불하며 일관성을 유지합니다.
- PA/EC (Partition-Availability / Else-Consistency): 장애 시에는 가용성을 택해 서비스 중단을 막으면서도, 평상시에는 강력한 일관성을 유지하려 노력하는 형태입니다. MongoDB의 기본 설정이나 관계형 DB의 비동기 복제 모드가 이 영역에 발을 걸치고 있습니다.
결국 PACELC은 아키텍트에게 “당신의 시스템은 위기의 순간에 무엇을 버릴 것이며, 평화로운 일상 속에서는 무엇을 위해 비용을 지불할 것인가?”를 묻습니다. 이 모델을 통해 우리는 시스템의 성격을 단순히 CP와 AP로 이분법화하는 수준을 넘어, 실질적인 운영 전략을 설계할 수 있는 정교한 틀을 갖게 됩니다.
실제 NoSQL 데이터베이스의 포지셔닝
현대의 데이터베이스들은 고정된 위치에 머물지 않습니다. 개발자가 설정(Configuration)을 통해 PACELC 스펙트럼 위에서 시스템의 위치를 직접 조정할 수 있도록 허용합니다.
특히 쿼럼(Quorum) 기반의 시스템인 Cassandra와 DynamoDB는 읽기/쓰기 성공 판정 기준을 조절함으로써 시스템의 성격을 PA/EL에서 PC/EC에 가까운 형태까지 유연하게 변모시킬 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
import com.datastax.oss.driver.api.core.CqlSession;
import com.datastax.oss.driver.api.core.DefaultConsistencyLevel;
import com.datastax.oss.driver.api.core.cql.SimpleStatement;
import software.amazon.awssdk.services.dynamodb.DynamoDbClient;
import software.amazon.awssdk.services.dynamodb.model.GetItemRequest;
import software.amazon.awssdk.services.dynamodb.model.AttributeValue;
import java.util.Map;
/**
* * 분산 시스템의 PACELC 이론 중 'Else(평상시)' 상황에서
* 지연 시간(Latency)과 일관성(Consistency) 사이의 균형을 조정하는 예제입니다.
*/
public class DistributedConsistencyManager {
/**
* 1. Apache Cassandra (Java Driver 4.x)
* QUORUM 설정을 통해 과반수 노드의 합의를 기다립니다.
* 이는 평상시(Else)에 지연 시간을 감수하고 일관성을 높이는(EC) 선택입니다.
*/
public void writeWithQuorum(CqlSession session, String key, String data) {
SimpleStatement statement = SimpleStatement.builder(
"UPDATE sensors SET value = ? WHERE id = ?")
.addPositionalValues(data, key)
// QUORUM: (복제 계수 / 2) + 1개 노드의 확인을 받아야 성공
// 일관성을 위해 지연 시간(Latency)이 소폭 증가합니다.
.setConsistencyLevel(DefaultConsistencyLevel.QUORUM)
.build();
session.execute(statement);
}
/**
* 2. AWS DynamoDB (AWS SDK for Java v2)
* Strongly Consistent Read 여부를 결정합니다.
*/
public void readFromDynamo(DynamoDbClient ddb, String tableName, Map<String, AttributeValue> key) {
// consistentRead(true): 가장 최신 데이터를 보장(EC)하지만 지연 시간이 늘어날 수 있음
// consistentRead(false): 지연 시간은 짧으나(EL) 데이터가 일시적으로 불일치할 수 있음
GetItemRequest request = GetItemRequest.builder()
.tableName(tableName)
.key(key)
.consistentRead(true)
.build();
ddb.getItem(request);
}
}
예를 들어, Write=All과 Read=All 설정을 사용하면 시스템은 매우 강력한 일관성을 보장하지만(EC), 단 하나의 노드만 느려져도 전체 응답 속도가 급락하는(L) 대가를 치릅니다. 반면 Write=1, Read=1 설정은 압도적인 속도를 보장하지만(L), 데이터 불일치가 빈번하게 발생하는 완연한 EL 아키텍처가 됩니다.
결국 PACELC은 엔지니어에게 다음과 같은 질문을 던집니다. “당신의 서비스는 1ms의 성능 향상을 위해 얼마나 많은 데이터 불일치를 허용할 수 있는가?” 혹은 “데이터 정합성을 위해 100ms의 지연 시간을 감수할 가치가 있는가?” 이 질문에 대한 답이 곧 해당 서비스의 아키텍처 그 자체가 됩니다.
Distributed Trade-offs
엔지니어링은 단순히 ‘더 나은 것’을 선택하는 과정이 아닙니다. 그것은 우리가 감당할 수 있는 ‘부작용’이 무엇인지 결정하는 치열한 협상에 가깝습니다. 분산 시스템에서 모든 것을 가질 수 있는 마법 같은 솔루션은 존재하지 않습니다. 아키텍트의 임무는 비즈니스의 생존에 가장 치명적인 화재가 무엇인지 파악하고, 그 반대편의 가치를 전략적으로 포기하는 것입니다.
완벽한 시스템은 없다
우리는 흔히 ‘강력한 일관성’과 ‘높은 가용성’을 동시에 추구해야 할 선(善)으로 여깁니다. 하지만 비즈니스 도메인에 따라 이 두 가치의 우선순위는 완전히 뒤바뀝니다.
결제 시스템이나 은행 송금 서비스에서 일관성은 타협 불가능한 가치입니다. 사용자의 잔액이 100원이라도 틀리게 표시된다면 그것은 서비스의 신뢰도 하락을 넘어 법적, 경제적 재앙으로 이어집니다. 이런 도메인에서는 네트워크 분단 시 차라리 서비스를 일시 중단(CP)하고, 평상시에도 엄격한 동기화(EC)를 거쳐 지연 시간을 감내하는 것이 정답입니다.
반면, 글로벌 SNS의 ‘좋아요’ 숫자나 실시간 스트리밍의 시청자 수 집계는 정반대의 길을 걷습니다. 내가 누른 ‘좋아요’가 지구 반대편 친구에게 1초 늦게 보인다고 해서 서비스가 망하지는 않습니다. 하지만 ‘좋아요’를 누를 때마다 시스템이 응답을 멈추거나 수 초간 로딩 바가 돌아간다면 사용자는 즉시 떠날 것입니다. 이들에게는 지연 시간을 최소화하고(EL) 언제나 응답을 주는 가용성(PA)이 데이터의 정밀도보다 훨씬 중요합니다.
지연 시간은 새로운 장애인가
전통적인 관점에서 ‘장애’는 서버가 다운되어 응답을 주지 못하는 상태를 의미했습니다. 하지만 현대의 분산 시스템에서 ‘느린 응답’은 ‘무응답’보다 더 고약한 형태의 장애입니다. 이를 ‘회색 장애(Gray Failure)’라고 부르기도 합니다.
특히 하위 0.1%의 요청이 겪는 지연 시간인 ‘P99.9 Latency(Tail Latency)’는 시스템 전체의 가용성을 갉아먹는 주범입니다. 수천 개의 마이크로서비스가 얽힌 환경에서 단 하나의 서비스가 평소보다 10배 느리게 응답하기 시작하면, 이 서비스를 호출하는 상위 서비스들의 스레드와 커넥션 풀이 하나둘씩 고갈되기 시작합니다. 이는 결국 상위 서비스의 타임아웃으로 이어지고, 최종적으로는 사용자 화면에 에러 페이지를 띄우는 연쇄 붕괴(Cascading Failure)를 일으킵니다.
지연 시간의 전염성
시스템이 완전히 죽어버리면 상위 서비스는 즉시 에러를 인지하고 서킷 브레이커(Circuit Breaker)를 작동시킬 수 있습니다. 하지만 ‘애매하게 느린’ 시스템은 상위 서비스의 자원을 끝까지 붙들고 늘어지며 시스템 전체를 서서히 질식시킵니다.
결국 아키텍트는 지연 시간을 단순히 성능의 문제로 보지 않고, 시스템 안정성을 위협하는 ‘잠재적 장애’로 간주해야 합니다. 성능과 일관성 사이의 트레이드오프에서 ‘성능’을 택하는 것은 단순히 빨라지기 위함이 아니라, 시스템의 탄력성(Resiliency)을 확보하기 위한 전략적 선택이 될 수 있습니다.
Summary
분산 컴퓨팅은 네트워크가 신뢰할 수 없고 지연 시간이 존재한다는 가혹한 현실을 인정하는 것에서 출발합니다. CAP 이론은 네트워크 분단이라는 위기 상황에서 우리가 마주할 선택의 한계를 명확히 규정하며, PACELC 이론은 평상시에도 지연 시간과 일관성 사이의 끊임없는 저울질이 필요함을 일깨워줍니다. 엔지니어의 역할은 정답이 없는 이 트레이드오프의 스펙트럼 위에서 비즈니스 가치를 극대화할 수 있는 최적의 지점을 찾아내는 것입니다. 기술적 선택에는 공짜가 없으며, 우리가 얻는 모든 성능과 신뢰 뒤에는 반드시 그에 상응하는 포기와 희생이 뒤따른다는 사실을 잊지 말아야 합니다.