[Retrospect] 문맥 기반 선별적 로깅을 활용한 대용량 트래픽 스토리지 최적화
본 문서는 ONOL 프로젝트 진행 중 수행된 “데이터 저장 정책 최적화(Smart Logging)” 작업에 대한 회고다. 실시간 동영상 스트리밍이나 대용량 파일 전송 시 발생하는 막대한 양의 패킷 데이터로 인한 스토리지 낭비와 Write I/O 병목 문제를 해결하기 위해, 모든 패킷을 저장하던 기존 방식에서 ‘가치 있는 데이터’만 선별하여 저장하는 방...
본 문서는 ONOL 프로젝트 진행 중 수행된 “데이터 저장 정책 최적화(Smart Logging)” 작업에 대한 회고다. 실시간 동영상 스트리밍이나 대용량 파일 전송 시 발생하는 막대한 양의 패킷 데이터로 인한 스토리지 낭비와 Write I/O 병목 문제를 해결하기 위해, 모든 패킷을 저장하던 기존 방식에서 ‘가치 있는 데이터’만 선별하여 저장하는 방...
본 회고는 로컬 네트워크 패킷 분석 시스템 개발 중 발생한 데이터 처리 지연 현상을 분석하고, 이를 아키텍처 관점에서 해결한 과정을 기술한다. 특히 대용량 트래픽 환경에서 발생한 Redis N+1 입출력 문제를 진단하고, Pipelining 및 Bulk 연산을 도입하여 시스템 처리량을 약 700% 향상시킨 경험을 중점적으로 다룬다. Problem C...
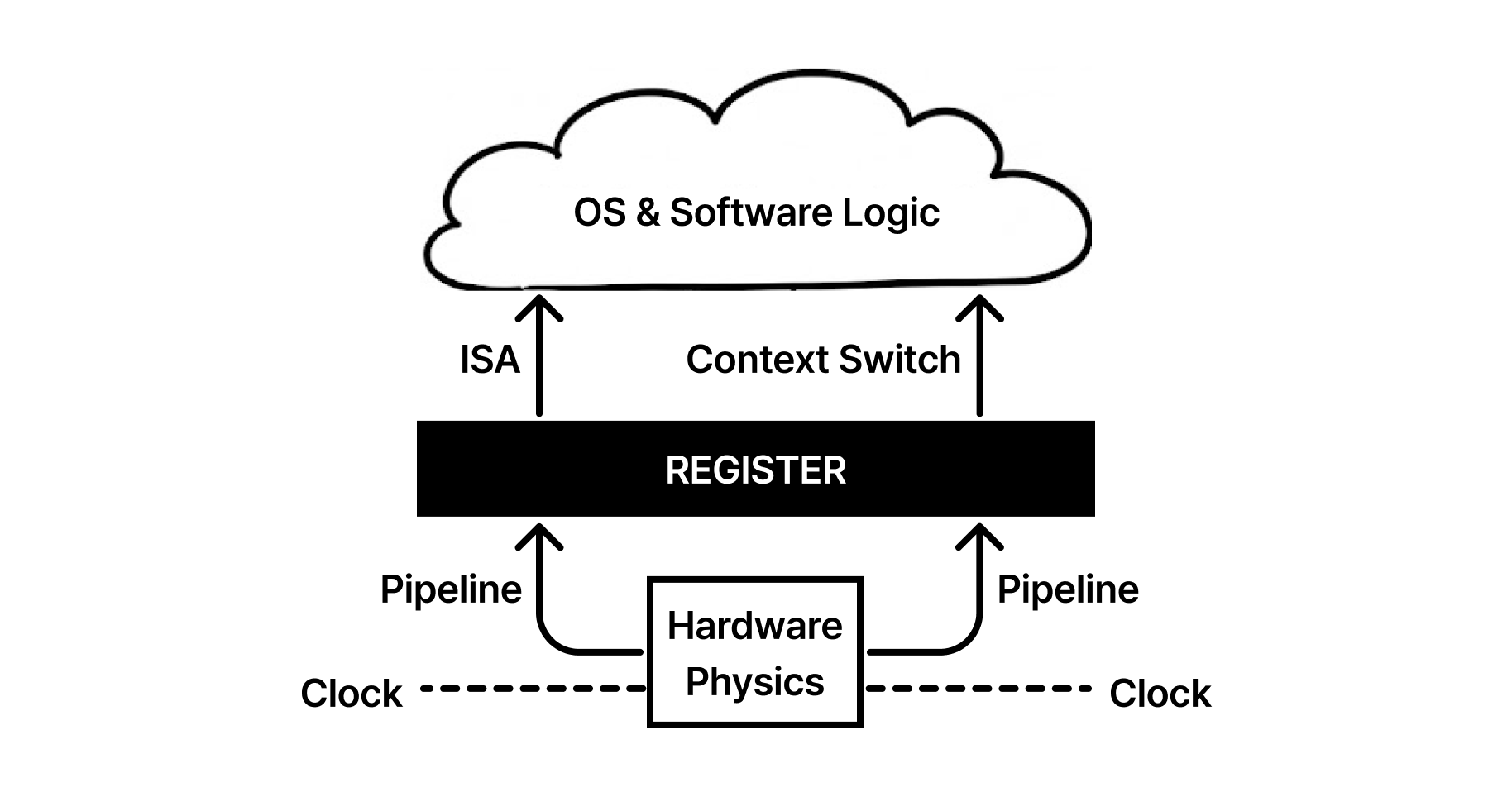
🧩 Memory Hierarchy 현대 컴퓨팅 아키텍처에서 성능의 병목은 연산 속도가 아닌 데이터의 이동 속도에서 발생합니다. 프로세서의 연산 성능이 아무리 높아도 필요한 데이터를 적시에 공급받지 못하면 CPU는 데이터를 기다리며 유휴 상태에 머물게 됩니다. 레지스터는 이러한 전송 지연 시간을 극복하기 위해 연산 장치 최전방에서 데이터를 관리합니다....
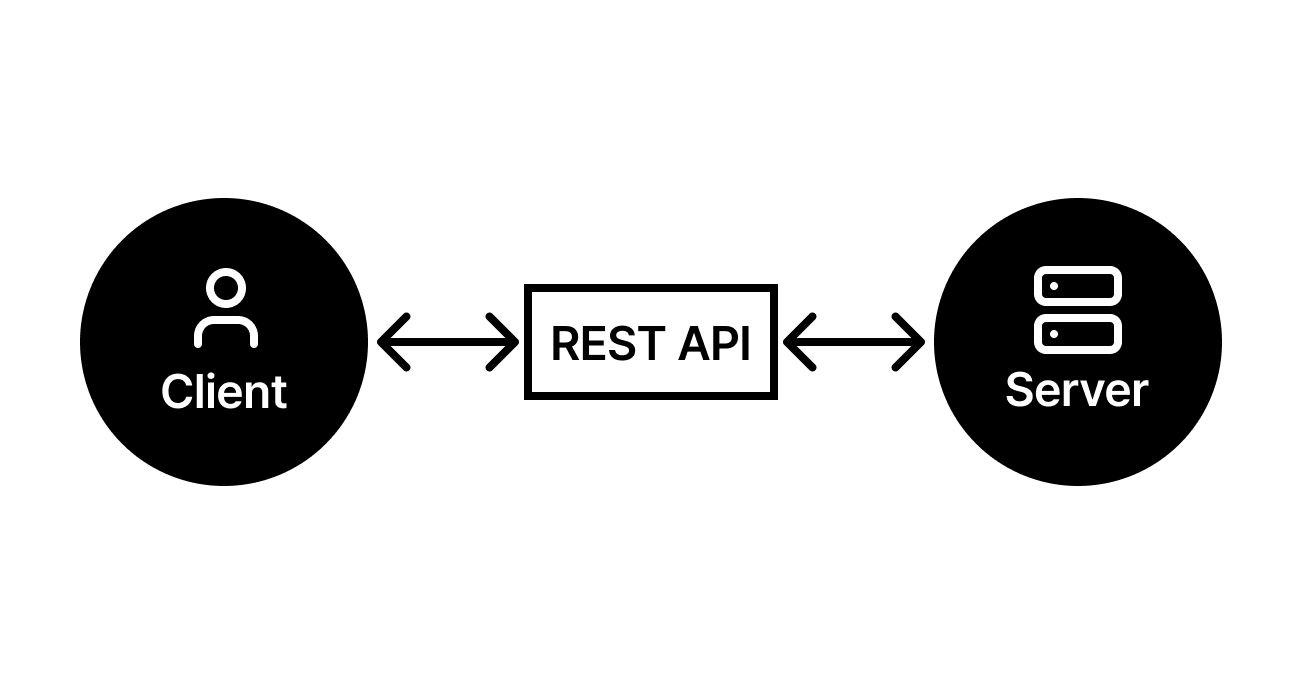
REST는 분산 하이퍼미디어 시스템을 위한 아키텍처 스타일입니다. 단순히 데이터 형식을 규정하는 것이 아니라, 시스템 구성 요소 간의 상호작용을 제약하여 장기적인 유지보수성과 확장성을 확보하는 데 목적이 있습니다. 로이 필딩(Roy Fielding)이 정의한 REST는 전 지구적 규모의 시스템이 수십 년간 붕괴하지 않고 진화할 수 있는 구조적 해답을 ...
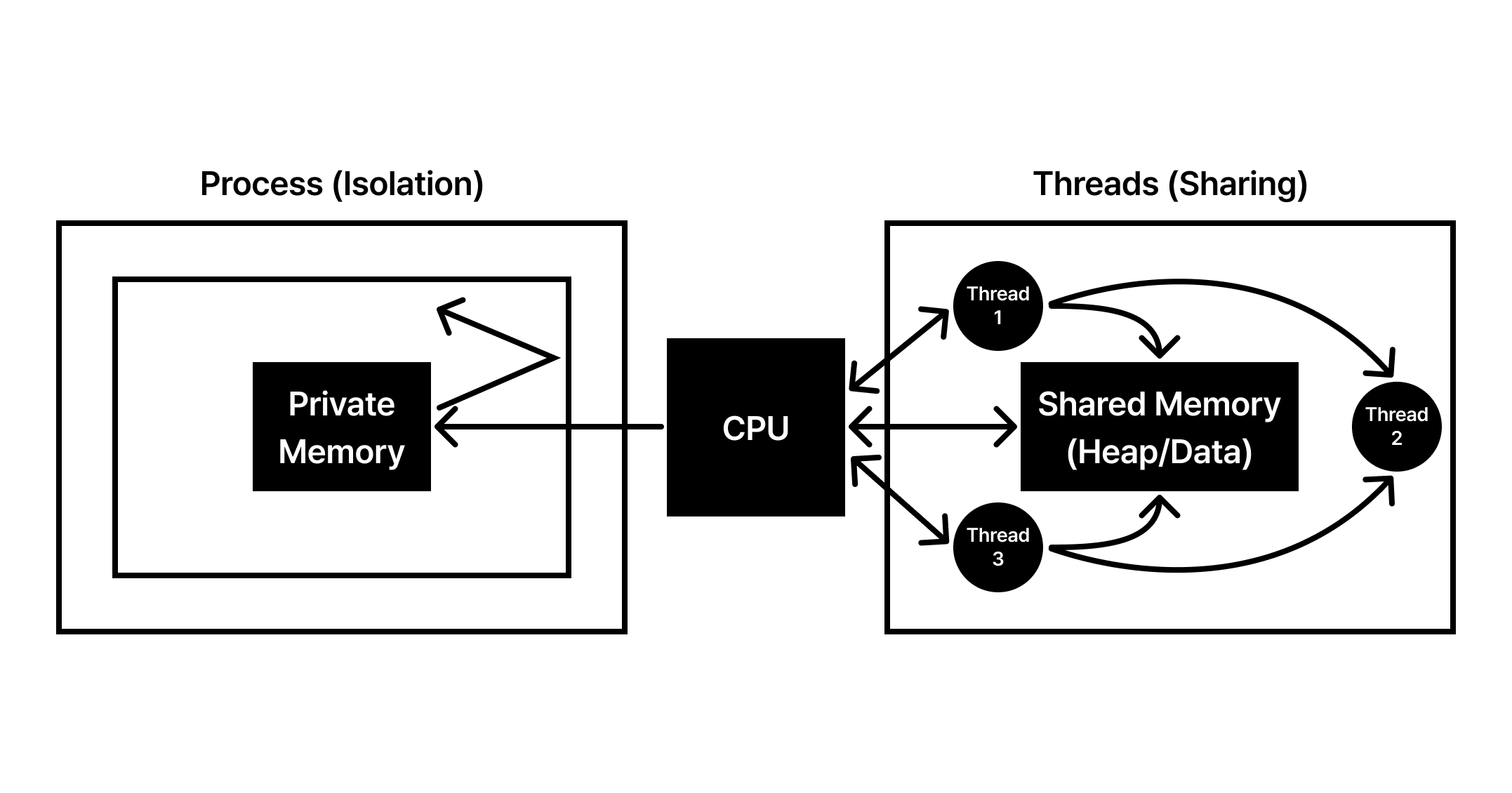
🧩 Process 운영체제는 실행 중인 프로그램인 프로세스를 통해 하드웨어 자원을 관리합니다. 여러 프로세스가 동시에 구동되는 환경에서 각 프로세스는 CPU와 메모리를 독점적으로 사용하는 것처럼 동작하며, 운영체제는 이를 위한 격리된 실행 환경을 보장합니다. 프로세스는 단순히 실행 중인 상태를 넘어, 시스템 자원을 안전하게 공유하기 위한 가장 기본적...
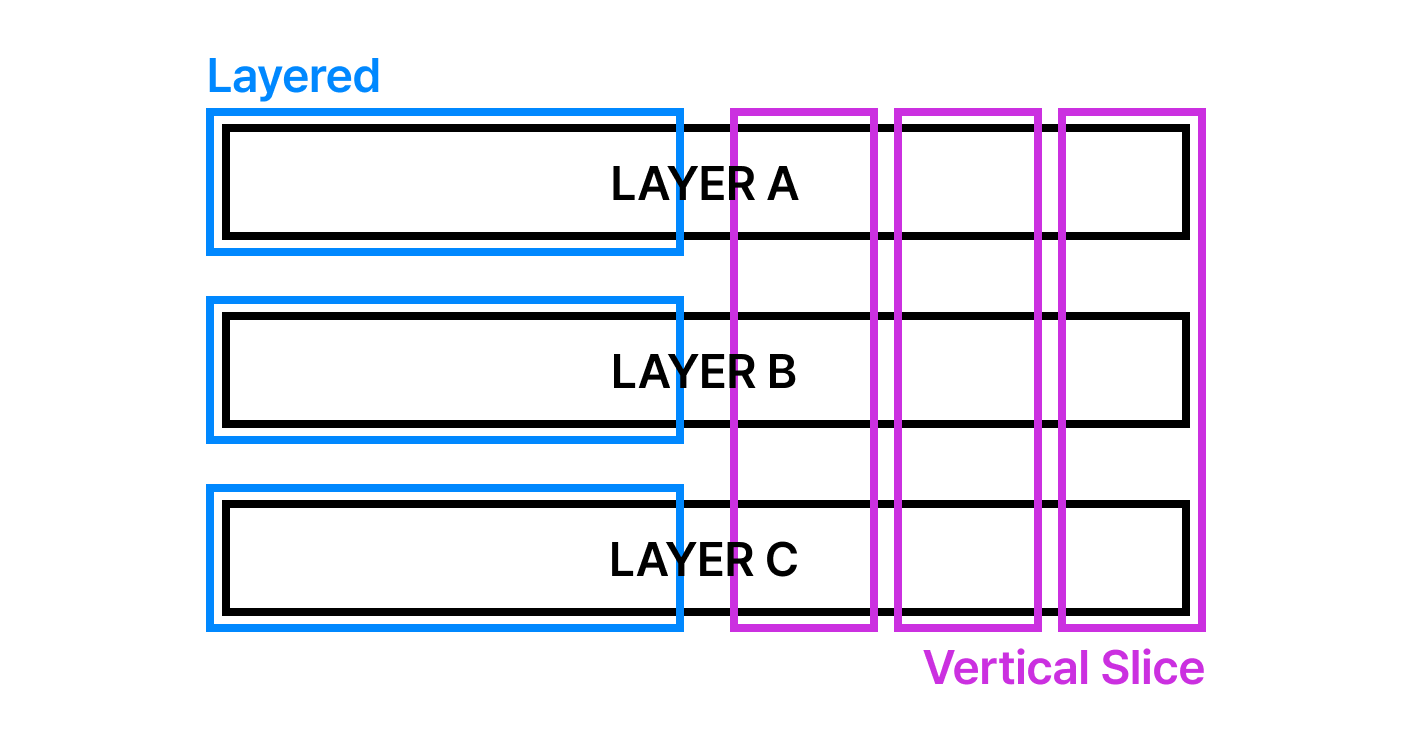
아키텍처를 논할 때 보통 모놀리식이나 마이크로서비스 같은 배포 구조를 떠올리지만, 진정한 의미의 아키텍처는 단일 프로세스 내의 코드 조직화(Internal Structure)에서 시작됩니다. 내부 아키텍처의 목표는 패턴의 적용 자체가 아니라 개발자가 코드를 읽을 때의 인지 부하(Cognitive Load)를 줄이고, 관련 로직을 가깝게 배치하여 응집...
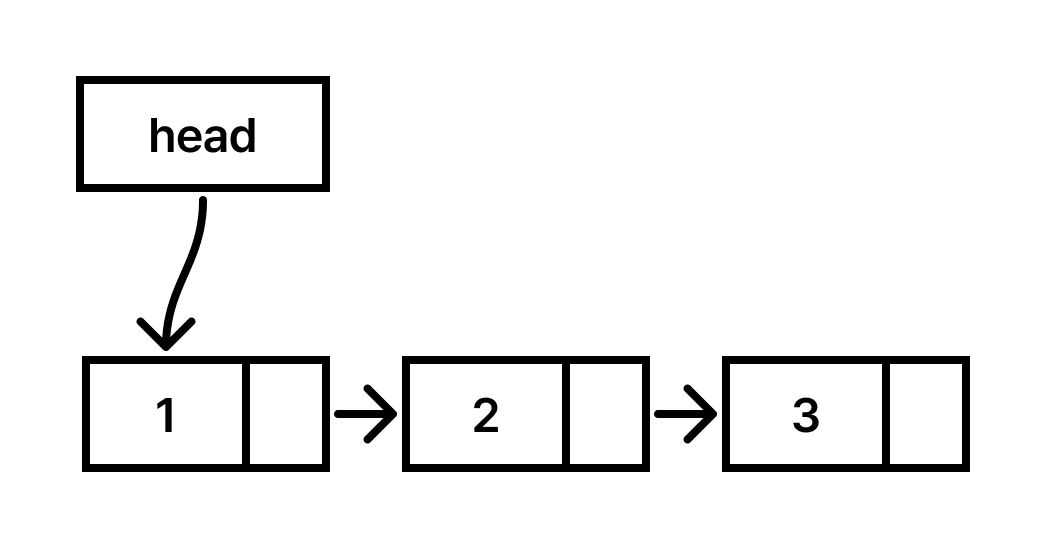
🧩 Linked List Linked List & Array 연결 리스트는 임의의 메모리 공간에 있는 요소를 연결하여 저장하는 자료구조입니다. 배열과의 비교를 통해 연결 리스트를 더 쉽게 이해할 수 있습니다. 배열은 연속된 공간에 요소를 저장합니다. C에서 다음과 같이 선언할 수 있습니다. int scores[100]; scores[0]...